Bigtable Paper Reading
Bigtable Paper Reading
资料推荐: 深入浅出BigTable, B站似乎也有搬运, 看不了YouTube的小伙伴可以搜一下.
Bigtable的设计目标是为了达到广泛的应用性, 可扩展, 高性能和高可用, 我将从这几个目标来谈谈我对这篇论文的理解.
可扩展
Bigtable是一个稀疏的、分布式的、持久的多维有序map,该map是基于行键(row key), 列键(column key), 时间戳(timestamp)三者建立索引的, map中的每个值都是一个未解释的字节数组. 每一条数据有一个行键, 通过行键可以原子性地读写一条数据. 一条数据包含了多个列族(column family), 不同行数据的同一列族内, 可以定义不同的列. 每一个列不仅可以保存值,而且可以保存多个版本,每个版本包含了一个时间戳。
列键被组织成一个叫列族的集合, 作为访问控制的基本单位. 存储在同一列族内的数据通常具有相同的类型, 在存储任何列键的数据之前必须先创建列族. 创建列族完成后, 列族中的任意列键都可以使用.

从上图我们可以看出bigtable的表设计是一张灵活的,"稀疏"表, 这对于早期互联网高速增长的业务来说是十分友好的. 如果采用MySQL集群存储数据, 一开始设计的方案不能满足业务的告诉增长, 就会面临数据倾斜, 部分服务器负载过高等问题.
举个论文中的例子:
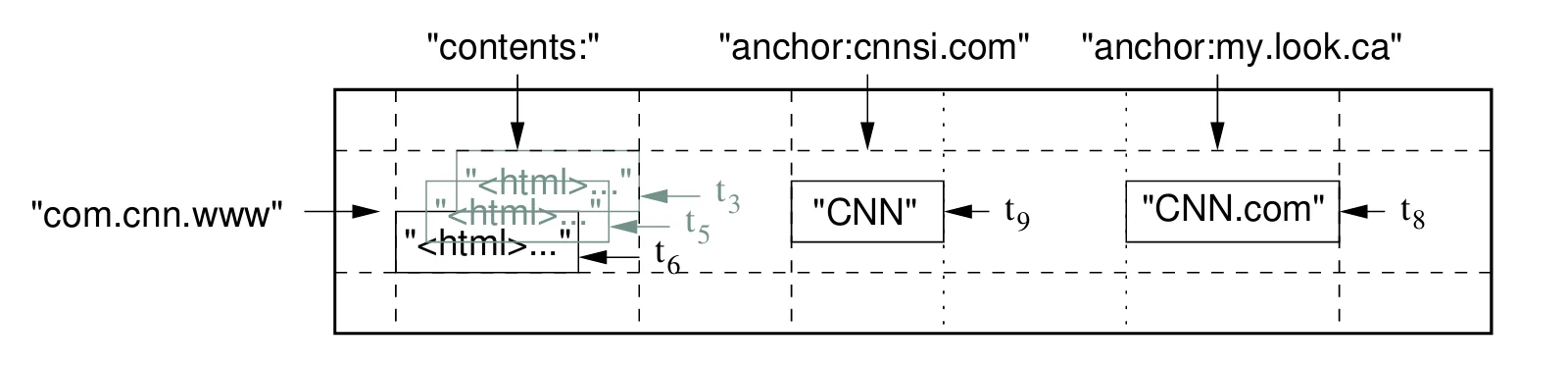
行键是URL, 列键是网页的不同部分, 如“contents”, 时间戳是页面抓取时间, 根据这三者就可以定位到特定的值.
动态分区
Bigtable通过将行键划分为大小相等的区域(Tablet)来分区, 每个Tablet包含一定范围内的行键. 当一个Tablet变得过大时, 它会被分割成两个区域, 当一个Tablet变得过小时, 它会与别的Tablet合并. 这种动态分区机制使得Bigtable可以水平扩展, 以适应不断增长的数据量. Chubby, Mater和Tablet Server共同合作完成数据的动态分区任务.
Tablet Server会由Master分配多个Tablet(Master可以根据每个 Tablet Server 的负载进行动态的调度, 起到负载均衡的作用), 其提供这些Tablets的读写服务, 并负责这些Tablets的分裂和合并. 分裂操作由Tablet Server发起, 而合并操作通常由Master发起, 因为可能涉及到多个Tablet Server. Master会周期性地向Tablet Server发送心跳信息, 以确保Tablet Server正常运行. 当Tablet Server宕机时, Master会将其负责的Tablets分配给其他Tablet Server.
Chubby的作用是: 保证任何时间只有一个Master、存储Bigtable数据的bootstrap location、tablet服务器的发现和服务器终止后的清理工作、存储Bigtable模式信息(每个table的列族信息)、存储访问控制列表. 如果我们只采用一台外部服务器来监控Master的存活, 误判的概率会很大, 从而导致数据不一致. 而一个Chubby服务由5个active replicas组成, 通过Paxos这样的共识算法来确保不会出现误判.
Master的作用是: 分配 Tablets给Tablet Server、检测Tablet Server的新增和过期、平衡 Tablet Server 的负载、对于 GFS 上的数据进行垃圾回收、管理表和列族的 Schema 变更, 比如表和列族的创建与删除.
高性能
高性能的写入
首先是将随机写入转化为顺序写入, 追加数据本身就是顺序写入, 修改数据就是写入新的数据来覆盖旧的数据, 删除数据就是写入一个旧数据的墓碑标记. 然后是不会直接将数据写入磁盘, 先会在GFS中写入日志, 完成后写入内存中的内存表(MemTable). 当内存表的大小达到阈值时,内存表被冻结, 一个新的内存表被创建, 然后被冻结的内存表会转化为一个SSTable并写入到GFS中, 这个过程是minor compaction. minor compaction有两个目标:它缩小了 tablet 服务器的内存使用量,并且如果此服务器死机,它减少了在恢复期间必须从提交日志中读取的数据量。在压缩发生时,传入的读写操作可以继续。
随着时间的推移, SStable会越来越多, Bigtable通过在后台定期执行合并压缩(merging compaction)来限制此类文件的数量。合并压缩会读取一些 SSTable 和 memtable 的内容,并写出新的 SSTable。压缩完成后,可以立即丢弃输入的 SSTable 和 memtable。
将所有SSTable重写为一个SSTable的合并压缩称为主要压缩(major compaction). 非主要压缩生成的 SSTable 可以包含特殊的删除条目(用于标记其中已经被删除的数据), 但实际上这些数据还没有被真正删除. 而major compaction产生的SSTable不会包含这些删除信息或者已删除的数据. Bigtable会定期地遍历所有tablets, 执行major compaction操作. 这使得Bigtable可以及时回收已删除的数据占用的资源.
高性能的读取
- 客户端可以将多个列族组合成一个位置组(locality group). 每个tablet中的每个位置组都会生成一个单独的SSTable. 将通常不一起访问的列族隔离到单独的位置组中可以提高读取效率.
- 将SSTable的索引加载到内存中, 这样可以快速定位到数据所在的SSTable.
- 客户端可以控制是否压缩某个位置组的 SSTable, 虽然我们通过单独压缩每个块会损失一些空间, 但可以无需解压整个文件即可读取 SSTable 的一小部分.
- 把每个 SSTable 的布隆过滤器直接缓存在 Tablet Server, 布隆过滤器可以过滤掉绝大部分不存在的数据, 从而减少磁盘IO.
- Tablet Server的两级缓存. 是一种高级缓存,Scan Cache用于缓存 SSTable 接口返回到 tablet 服务器代码的键值对。Block Cache是一种低级缓存,用于缓存从 GFS 读取的 SSTables 块。
高可用
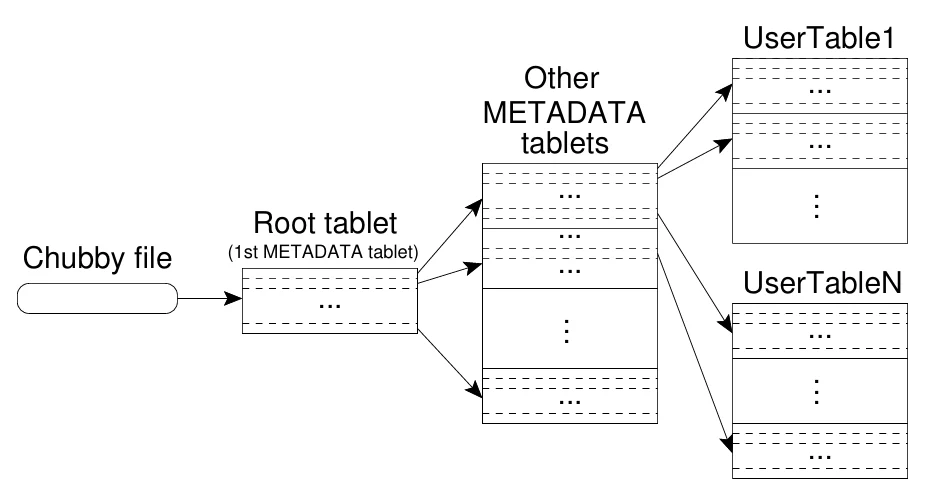
Bigtable通过设计将Master排除在了整个数据读写的过程中, 将查询Tablets尽可能地被分摊到了Bigtable的整个集群, 从而保证了高可用性.
Bigtable把分区和Tablets的分配信息存在Bigtable集群里的METADATA表. Bigtable 在 Chubby 里的一个指定的文件里,存放了一个叫做Root Tablet的分区所在的位置。这个Root Tablet的分区,是METADATA表的第一个分区,这个分区永远不会分裂(保证存储tablet的位置信息的结构不超过三层)。它里面存的是METADATA里其他Tablets所在的位置。而METADATA剩下的这些Tablets,每一个Tablet中,都存放着User Tablets的位置。
查询过程:
- 客户端首先访问Chubby,获取
Root Tablet的位置。 - 客户端使用Root Tablet的位置信息,查询出具体
METADATA Tablet的位置。 - 客户端使用
METADATA Tablet的位置信息,查询出User Tablets的位置。 - 客户端使用
User Tablets的位置信息,查询出具体的数据。
METADATA table的每行数据在内存中大约占 1KB。如果将 METADATA tablet 限制在 128MB ,这种三层结构就可以存储高达 2^34个tablets和2^61 bytes
通过上面的设计, Bigtable达到了可扩展, 高性能和高可用, 正如它的名字一样, 这是一张"大"表, 所以它必然拥有广泛的应用性.

