HDFS Paper Reading
HDFS Paper Reading
我认为HDFS是一个更加通用的开源的GFS, 其架构和设计思路与GFS非常相似, 但是HDFS在实现上更加简单, 更加通用, 所以我会关注常见的问题和显著不同的地方.
HDFS写流程
- 客户端发送写请求, 通过RPC与NameNode建立通信, NameNode检查该用户是否有写权限, 以及写入的文件是否在HDFS对应的目录下重名, 如果这两者有任意一个不满足, 则直接报错, 如果两者都满足, 则授予客户端一个写入租约(lease)
- Client根据文件的大小进行切分, 默认128M一块, 切分完成之后给NameNode发送请求第一个block块写入到哪些服务器上
- NameNode收到请求之后, 根据网络拓扑和机架感知以及副本机制进行文件分配, 返回可用的DataNode的地址
- 客户端收到地址之后与服务器地址列表中的一个节点进行通信, 建立pipeline, Client->DN0->DN1->DN2
- Client向DN0以packet(64kb)形式传输数据, 然后沿着pipeline传输, ack响应会沿着pipeline逆序返回, 直到DN2收到数据, DN2向DN1发送ack, DN1向DN0发送ack, DN0向Client发送ack
- 当Client收到DN0的ack之后, 意味着对应的packet传输完成, 整个block传输完成后, Client再次请求NameNode上传第二个block
从写流程中我们便能看出一些HDFS与GFS的相同之处, 也有一些不同之处
GFS和HDFS中的租约(lease)机制是相同的吗?
不相同. GFS使用租约机制来确保对数据块的写入操作是有序的, 它会指定一个副本作为主副本, 主副本负责为所有对该数据块的写操作分配一个全局的序列号,来保证写入的顺序性; 而HDFS中的租约机制则用于确保单个客户端对文件的写入操作的独占性. 当一个客户端打开一个文件进行写入时, 它会获得一个租约. 这个租约确保在租约有效期内, 没有其他客户端可以写入同一个文件.
GFS和HDFS中的pipeline传输机制是相同的吗?
几乎相同, 只不过GFS中存在主次副本的概念, Client传输(写入)的第一个对象就是主副本, 而HDFS中副本之间是平等的, 所以Client会将数据第一个传给离它最近的NameNode.
HDFS和GFS的一致性
HDFS的一致性比GFS强一些, HDFS在文件完成写入后是不可变的(更准确地说, HDFS的文件在关闭之后不能被覆盖或在任意位置修改), 而GFS在文件完成写入后是可以修改的. 有人会问HDFS不是支持文件追加吗? 怎么是不可变呢? 和GFS的记录追加有什么区别呢? 主要的区别是GFS中的记录追加是为了并发写入而设计的, 它只能保证至少一次的一致性, 多个副本之间的数据是有可能不相同的(这种不一致是暂时的, 最终会通过内部机制达成一致); HDFS不支持对同一文件的并发写入, 它的文件追加是顺序写入, 能够做到恰好一次, 每个副本之间的数据是相同的, 所以HDFS的一致性更好.
可用性
HDFS论文中提到了CheckpointNode和BackupNode. CheckpointNode(也称为Secondary NameNode, 中文的资料中主要提的是这个)的主要作用是CheckpointNode会定期从NameNode接收编辑日志(EditLog)和文件系统镜像(FSImage), 然后合并它们, 生成一个新的FSImage, 并将这个新的FSImage发送回NameNode. 这个过程有助于减少EditLog的大小, 防止其无限增长, 从而避免NameNode在启动或恢复时需要处理巨大的EditLog, 提高了系统的稳定性和恢复速度. BackupNode可以作为NameNode的热备份, 存储NameNode的元数据的副本, 以便在NameNode故障时快速恢复.
但这两种方案都是Hadoop早期的做法, 在Hadoop 2.x版本中, NameNode引入了高可用(HA)特性, 通过配置Active NameNode和Standby NameNode, 可以实现NameNode的自动故障转移, Standby NameNode实时同步Active NameNode的状态, 确保在Active NameNode故障时能够迅速切换, 保证服务的连续性, 提高了系统的可用性和可靠性. 在Hadoop 3.x版本中, NameNode引入了联邦(Federation)特性, 可以将多个NameNode组成一个集群, 每个NameNode管理一部分命名空间, 这样解决了NameNode内存瓶颈问题, 提高了系统的扩展性和性能.
下面这是一张Hadoop 2.x版本中的高可用架构图, 3.x版本只比它多增加了一些NameNode的配置
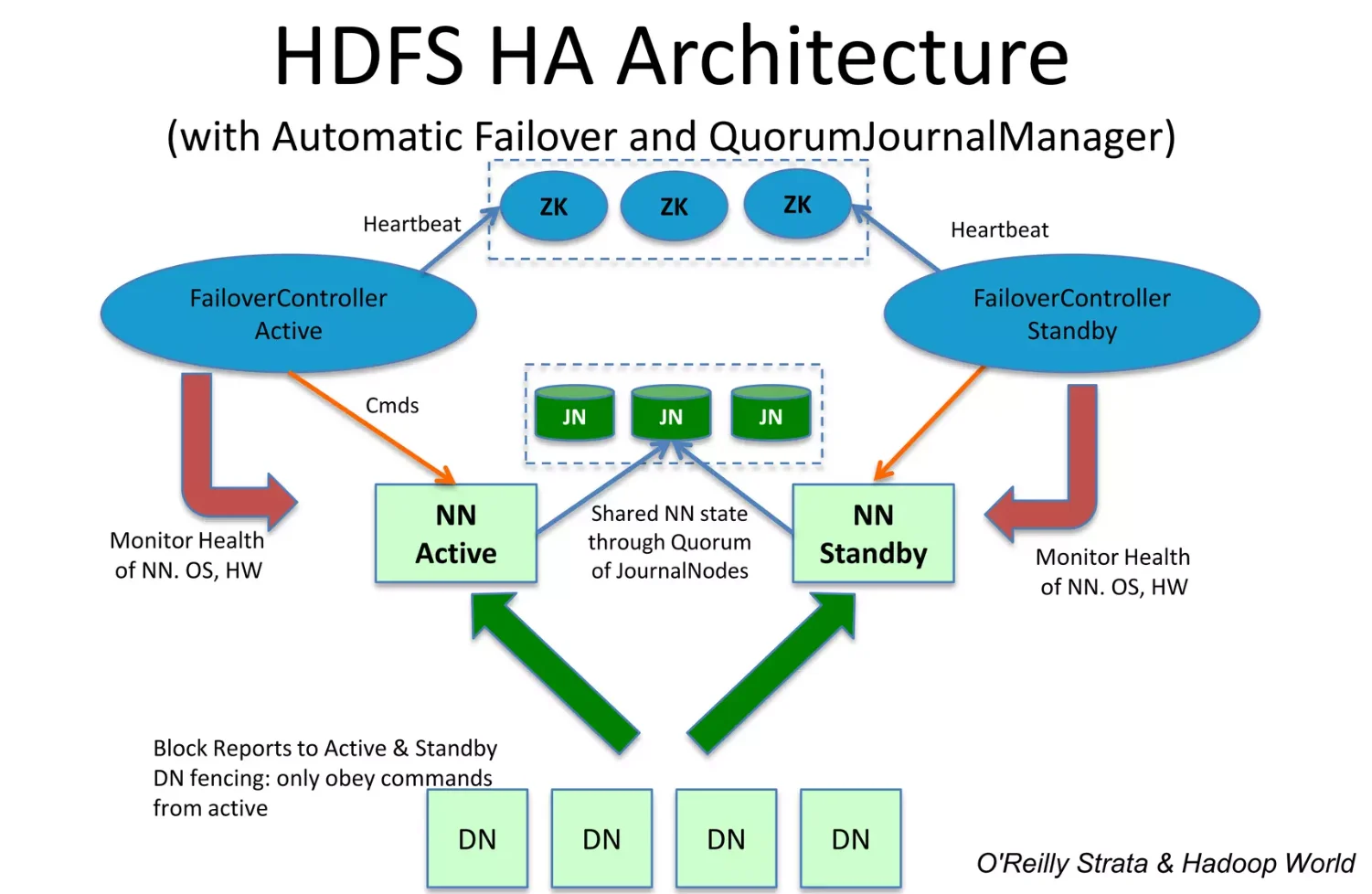
监控NameNode状态采用zookeeper, 两个NameNode节点的状态存放在zookeeper中, 另外两个NameNode节点分别有一个进程监控程序, 实施读取zookeeper中有NameNode的状态, 来判断当前的NameNode是不是已经挂了. 如果Standby的NameNode节点的ZKFC发现主节点已经挂掉, 那么就会强制给原本的Active NameNode节点发送强制关闭请求, 之后将备用的NameNode设置为Active.
元数据信息同步在 HA 方案中采用的是共享存储, 每次写文件时, 需要将日志同步写入共享存储, 这个步骤成功才能认定写文件成功. 然后备份节点定期从共享存储同步日志, 以便进行主备切换. 共享存储采用的是基于QJM(Quorum Journal Manager)的方案, QJM共享存储的基本思想来自于Paxos算法, 采用多个称为JournalNode的节点组成的JournalNode集群来存储EditLog. 每个JournalNode保存同样的EditLog副本. 每次NameNode写EditLog的时候, 除了向本地磁盘写入EditLog之外, 也会并行地向JournalNode集群之中的每一个JournalNode发送写请求, 只要大多数的JournalNode节点返回成功就认为向JournalNode集群写入EditLog成功. 如果有2N+1台JournalNode,那么根据大多数的原则, 最多可以容忍有N台JournalNode节点挂掉.
常见问题
HDFS读流程
- Client向NameNode发送读请求
- NameNode收到请求之后会检查用户权限以及是否有这个文件, 如果都符合, 则会视情况返回部分或全部的block列表, 对于每个block, NameNode都会返回含有该block副本的DataNode地址; 这些返回的DataNode地址, 会按照集群拓扑结构得出DataNode与客户端的距离, 然后进行排序(规则: 网络拓扑结构中距离Client近的排靠前; 心跳机制中超时汇报的DataNode状态为STALE, 这样的排靠后)
- Client选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性)
- 当读完列表的block后, 若文件读取还没有结束, 客户端会继续向NameNode获取下一批的block列表
- 读取完一个block都会进行checksum验证, 如果读取DataNode时出现错误, 客户端会通知NameNode, 然后再从下一个拥有该block副本的DataNode继续读
- 最终读取来所有的block会合并成一个完整的最终文件
NameNode在启动的时候会做哪些操作?
首次启动NameNode:
- 格式化文件系统, 生成fsimage镜像文件
- 启动NameNode:
- 读取fsimage文件, 将文件内容加载进内存
- 等待DataNade注册与发送block report
- 启动DataNode:
- 向NameNode注册
- 发送block report
- 检查fsimage中记录的块的数量和block report中的块的总数是否相同
- 对文件系统进行操作(创建目录/上传文件/删除文件等):
- 此时内存中已经有文件系统改变的信息, 但是磁盘中没有文件系统改变的信息, 此时会将这些改变信息写入edits文件中, edits文件中存储的是文件系统元数据改变的信息
非首次启动NameNode:
- 读取fsimage和edits文件
- 将fsimage和edits文件合并成新的fsimage文件
- 创建新的edits文件, 内容开始为空
- 启动DataNode
Secondary NameNode(CheckpointNode)的工作机制是怎样的?
- Secondary NameNode询问NameNode是否需要checkpoint
- Secondary NameNode请求执行checkpoint
- NameNode滚动正在写的edits日志(写到新的日志文件)
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载编辑日志和镜像文件到内存, 并合并
- 生成新的镜像文件fsimage.chkpoint
- 拷贝fsimage.chkpoint到NameNode
- NameNode将fsimage.chkpoint重新命名成fsimage
在NameNode HA中,会出现脑裂问题吗?怎么解决?
有可能会出现脑裂, 但概率比较小. 假设NameNode1当前Active状态, NameNode2当前为Standby状态. 如果某一时刻NameNode1对应的ZKFailoverController进程发生了"假死"现象, 那么 Zookeeper服务端会认为NameNode1挂掉了, 根据前面的主备切换逻辑, NameNode2会替代NameNode1进入Active 状态. 但是此时NameNode1可能仍然处于Active状态正常运行, 这样NameNode1和NameNode2都处于Active状态, 都可以对外提供服务, 即发生了脑裂.
会采用隔离的解决方案, 即把旧的 Active NameNode 隔离起来, 使它不能正常对外提供服务:
- 首先尝试调用这个旧Active NameNode的 HAServiceProtocol RPC 接口的
transitionToStandby方法, 看能不能把它转换为Standby状态 - 如果 transitionToStandby 方法调用失败, 那么就执行 Hadoop 配置文件之中预定义的隔离措施, Hadoop 目前主要提供两种隔离措施,通常会选择
sshfence:
- sshfence: 通过 SSH 登录到目标机器上, 执行命令 fuser 将对应的进程杀死
- shellfence: 执行一个用户自定义的 shell 脚本来将对应的进程隔离

