GFS Paper Reading
GFS Paper Reading
架构(Architecture)
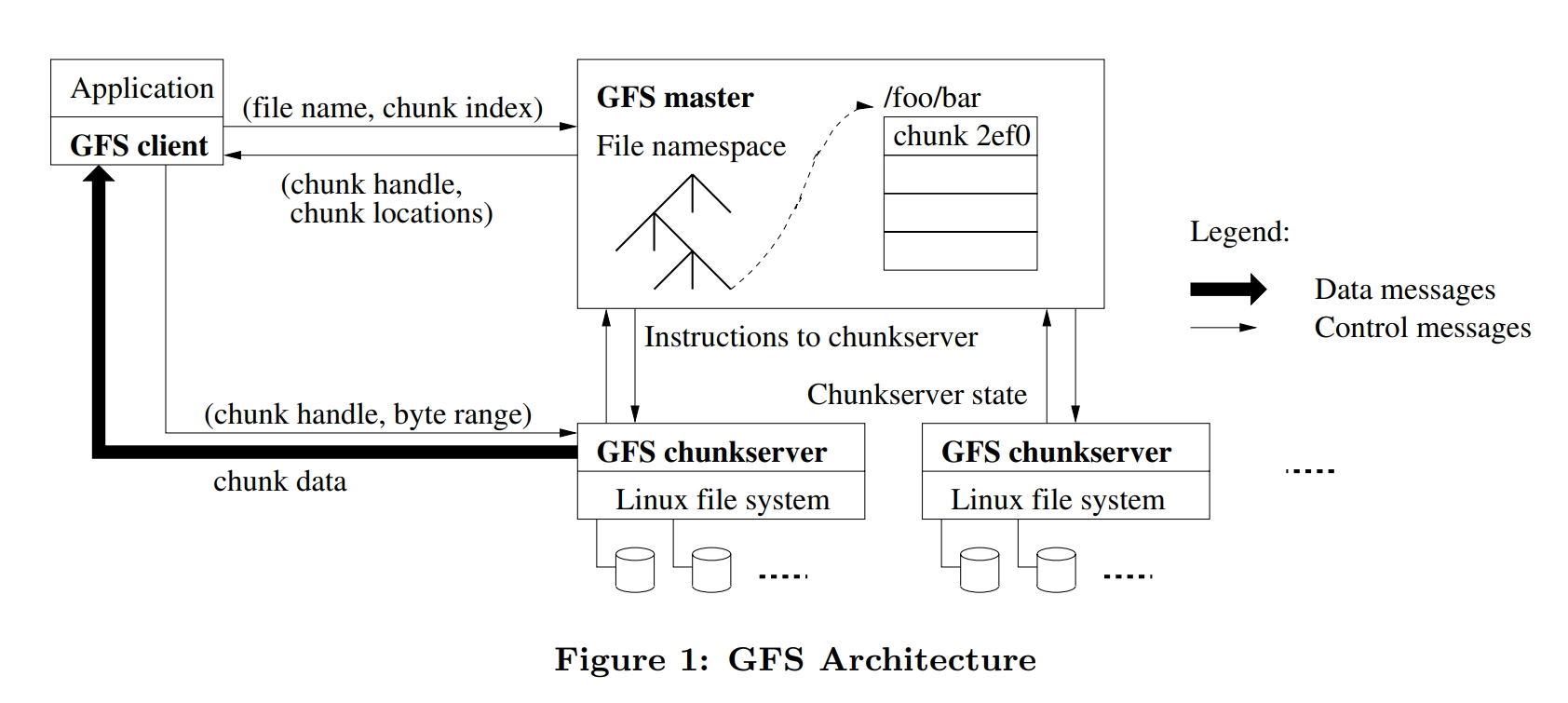
GFS采用单Master架构, 由master和chunkserver这两类服务器组成, master是主控节点, 而chunkserver是存储数据的节点, 其实就是Linux服务器. GFS使用Linux上的文件作为基础存储层, 通过命名空间+文件名来定义一个文件. 文件按每64M划分为一个chunk, 每个chunk都自己的唯一标识(chunk handle). 为了确保数据不会因为某一个chunkserver坏了就丢失了,每个chunk都会有三份副本(replica). 其中一份是主副本(primary), 两份是次副本(secondary), 当三份副本出现不一致的时候, 就以主副本为准. 有了三个副本,不仅可以防止因为各种原因丢数据, 还可以在有很多并发读取的时候, 分摊系统读取的压力
Master会存放三种元数据: 文件和chunk的命名空间信息, 文件名和chunk handle的映射关系(文件被拆分成了哪几个chunk), chunk handle和chunkserver的映射关系(chunk被存储在哪个chunkserver中).
客户端想要读取GFS中的文件的步骤:
- 客户端先去问 master,我们想要读取的数据在哪里。这里,客户端会发出两部分信息,一个是文件名,另一个则是chunk index, 因为客户端知道自己所要读取的数据的偏移量(offset)和长度, 它可以算出需要的是这个文件的哪几个chunk
- master 拿到了这个请求之后,就会把这些chunk的chunk handle和对应的所有副本所在的位置,告诉客户端。
- 客户端发送chunk handle和byte range向对应的chunkserver(通常是离得最近的chunkserver)请求读取数据
- chunkserver读取数据并返回给客户端
看完上面你可能会觉得GFS的设计十分简单, 确实如此, 那么代价是什么呢? 代价就是master的压力会很大, master需要承受数百台客户端的并发访问, 于是Google决定将master中的数据存储在内存中, 以提高性能. master中存储的信息是非持久化的, 它会通过周期的心跳检测保证存储的是最新的信息.
可用性保障(Availability assurance)
master节点如果挂掉了怎么办呢? 首先设计了可恢复机制, GFS在日志增长超过一定的大小的时候会对对当前状态设置一个checkpoint, 然后会把日志和checkpoint存储在磁盘上, 当master挂掉之后, 可以从checkpoint和日志中恢复状态, checkpoint的目的缩短恢复的时间, 回到一个较新的状态再根据操作日志恢复比从头根据日志恢复要快得多.
那如果硬件出问题, master无法恢复怎么办呢? GFS为master准备了几个备胎, 即backup master, master 的所有修改, 都需要同样写到backup master上. 只有当数据在 master上操作成功, 对应的操作记录持久化到硬盘上, 并且backup Master的数据也写入成功, 并把操作记录持久化到硬盘上, 整个操作才会被视为操作成功, 这就是同步复制. 如果要切换master, 为了实现无感的切换, GFS通过一个规范名称(Canonical Name)来指定master,而不是通过IP地址或者Mac地址. 这样, 只需要修改DNS的别名, 就能达到目的.
在恢复master的等待时间内, 就不能提供任何服务了吗? 对于写入服务, 确实如此, 但对于读取服务, GFS提供了只读的shadow master(异步复制). shadow master中的数据不一定和master以及backup master完全一致, 因为数据在master和backup master上写入完成就算真正成功了, shadow master的数据可能还没有更新, 但它会尽量与master保持一致. 想要读到有问题的数据的概率是不大的, 需要满足三个条件: 1. master挂了 2. master的日志还没有同步到backup master 3. 要读的数据恰好是还没有更新的那部分
交互
由于master的性能瓶颈, 我们需要尽量减少其他节点(client,chunkserver)和master之间的交互, 于是设计了租约和数据流与控制流分离. 租约是master对primary replica(主副本)对变更顺序的授权, 因为我们需要写入三份. 一个写入流程如下图:
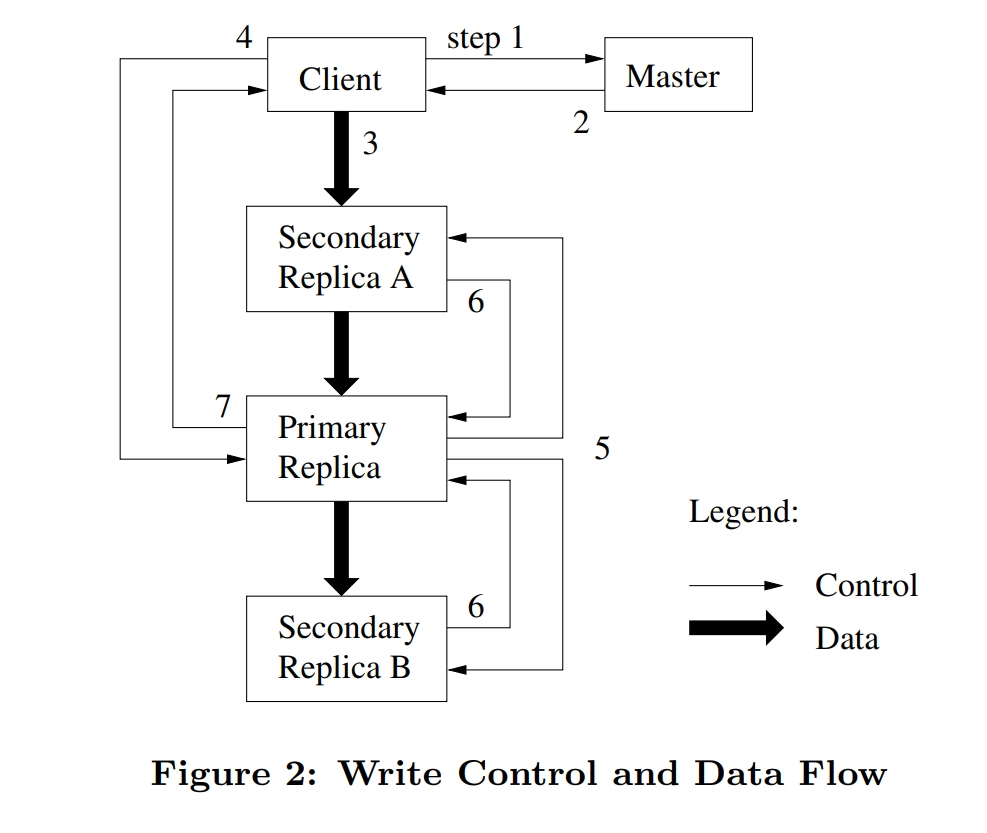
具体流程如下:
- 客户端会请求master哪一个chunkserver持有当前的租约, 以及其他的副本位置. 如果没有副本持有租约, master会选一个副本授权租约给它. 客户端在询问master数据应该写到哪里
- master会返回给客户端所有主副本和次副本的相关信息
- 客户端会把要写的数据发给所有的副本. 不过此时, chunkserver拿到发过来的数据后还不会真的写下来, 只会把数据放在一个LRU(Least Recently Used)的缓冲区里
- 一旦副本确认收到了数据, 客户端会发一个写请求给主副本. 该请求标识了之前推送给所有副本的数据. 然后主副本会分配一个连续的序列号给所有它接受到的变更(可能来自于多个client). 然后主副本会将按照前面的序列号将变更应用到本地的副本上
- 主副本会把对应的写请求转发给所有的次副本, 所有次副本会和主副本以同样的数据写入顺序, 把数据写入到硬盘上
- 等其他副本都写入完成了, 会返回给主副本操作完成
- 主副本会响应给客户端. 任何副本碰到的错误信息都会返回给client. 出现错误时, 写操作可能已经在主副本以及部分副本上执行成功了(如果是主副本失败了,就不会有变更的序列号分配给其他的副本也就是不会有后面的操作了). 如果遇到错误, 那么客户端的请求会被认为是失败的, 修改的region认为是处于不一致的状态. 我们客户端的代码代码会通过重试这些变更来处理这样的错误. 它会先在3-7步骤进行一些尝试后再从头重试写操作.
控制流和数据流的分离使得实际的数据传输过程和提供写入指令的动作是完全分离的. 客户端会将数据推送到最近的chunkserver, 然后这个chunkserver再推送到最近的另一个chunkserver, 依次类推, 实现链式的数据推送, 不采用客户端推送给全部chunkserver的做法充分利用了每台机器的带宽, 并且有效降低了延迟
GFS还为文件复制设计了一个Snapshot指令, 这个指令会通过控制流, 下达到主副本服务器, 主副本服务器再把这个指令下达到次副本服务器, 各个chunkserver会将本地的对应的chunk复制一份, 不需要传输数据. 如果没有这个指令, 客户端需要将文件从chunkserver读取回来, 再写入到chunkserver中去, 这极大地节省了时间和网络资源.
一致性(Consistency)
文件的namespace的变更是原子性的. 他们只被master处理: 命名空间锁保证了原子性和准确性; master的操作日志定义了全局全部操作的顺序.

- 如果数据写入失败, GFS里的数据就是不一致的.
- 如果客户端的数据写入是顺序的, 并且写入成功了, 那么文件里面的内容就是确定的(Defined, 即客户端写入GFS的数据能够完整的被读取).
- 如果由多个客户端并发写入数据,即使写入成功了, GFS 里的数据也可能会进入一个一致(无论从哪个副本读的数据都是相同的)但是非确定的状态.
为什么会出现第三种情况呢? 主要原因有两点: 一是数据写入的顺序是由主副本来管理的, 并不需要通过master; 二是数据的写入往往要跨越多个chunk. 比如说针对相同的数据写, 先前的变更会被新的变更所覆盖, 这样会导致读取到两次变更组合后的结果. 所以我们需要尽量避免随机的数据写入, 可以从客户端入手来保证写入的顺序性.
如果说让客户端保证写入的顺序性, 那GFS支持并发读写不就是一个笑话吗? 这是是因为随机写入并不是GFS设计的主要的数据写入模式, GFS设计了记录追加(Record Appends), 这是 GFS 希望我们主要使用的数据写入的方式, 由覆盖写改为了追加写, 牺牲一部分存储空间来保证一致性.
记录追加首先会检查当前的chunk是不是可以写得下现在要追加的记录. 如果当前chunk已经写不下了, 那么它先会把当前chunk填满空数据后, 主副本会告诉客户端,让它去下一个chunk继续追加. 追加的记录大小需要控制在trunk最大值的四分之一以内,以保证最坏情况下的碎片在一个可以被接受的等级, 即最后一个chunk会留出最多四分之一的空间来为了之后的记录追加, 四分之一是在高效的追加和空间浪费直间的权衡.
如果在主副本上写入成功了, 但是在次副本上写入失败了怎么办呢? 这样不是还会出现数据不一致的情况吗? 在前面我们提到出现这种会让客户端重试, 即使在有些副本上同样的内容写入了多次, 但我们保证了数据至少被写入了一次, 所以数据不会丢失. 对于Google的使用场景来说, 同样的网页被存储了两次并不是什么大问题, 可以在排序后进行去重
. 这个至少一次的机制虽然牺牲了一定的可用性, 但保证了高并发和高性能

