Redis线程模型
Redis线程模型和IO多路复用
Redis是单线程的吗?
redis6.0后,全面支持多线程。redis单线程指的是 接收请求、解析请求、进行数据读写操作、返回数据给客户端这个过程是由一个线程来完成的以及Redis的网络IO是由一个线程来完成的。所以我们称redis为单线程。
但是redis服务在启动的时候,会启动后台线程,常见的有两个
- 后台刷盘线程:当我们配置AOF策略为everysec时,每隔一秒,由后台线程完成刷盘操作
- 后台释放内存线程:redis 提供unlink命令,异步释放内存,特别是大key
之所以有后台线程,只为了不让主线程去执行这些操作,避免阻塞主线程,无法响应请求。
Redis为什么采用单线程?
Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,所以 Redis 核心网络模型使用单线程并没有什么问题,而且单线程避免了多线程之间并发竞争问题,省去了多线程切换带来的时间和性能上的开销,也不会导致死锁问题。
Redis 6.0引入多线程后,会产生并发安全问题吗?
不会,引入的多线程只是针对网络IO,在执行命令的时候,仍然是单线程执行
Redis 6.0 之后为什么引入了多线程?
虽然 Redis 的主要工作(网络 I/O 和执行命令)一直是单线程模型,但是在 Redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上。
所以为了提高网络 I/O 的并行度,Redis 6.0 对于网络 I/O 采用多线程来处理。对于命令的执行,Redis 仍然使用单线程来处理,不要误解 Redis 有多线程同时执行命令。Redis 官方表示,Redis 6.0 版本引入的多线程 I/O 特性对性能提升至少是一倍以上。
Redis 采用单线程为什么还这么快?
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,
- Redis 采用单线程模型避免了多线程之间并发竞争问题,省去了多线程切换带来的时间和性能上的开销,也不会导致死锁问题。
- Redis 采用了 I/O 多路复用的网络模型,来处理客户端产生的事件,即让一个线程同时与多个已完成连接socket进行通信,所以称为多路复用。用户态的线程怎么感知呢?实现这一机制的核心是:内核提供的 select() / epoll() 系统调用函数,来允许Redis 只运行单线程的情况下,同时和多个已完成连接的 Socket进行通信。让处于用户态的线程,发现请求网络事件的socket,线程才可以做出相应的处理.类似于CPU并发调度线程,一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流(客户端连接)的效果。
Redis 单线程模式是怎样的?(难点)
Redis 6.0 版本之前的单线程模式如下图:
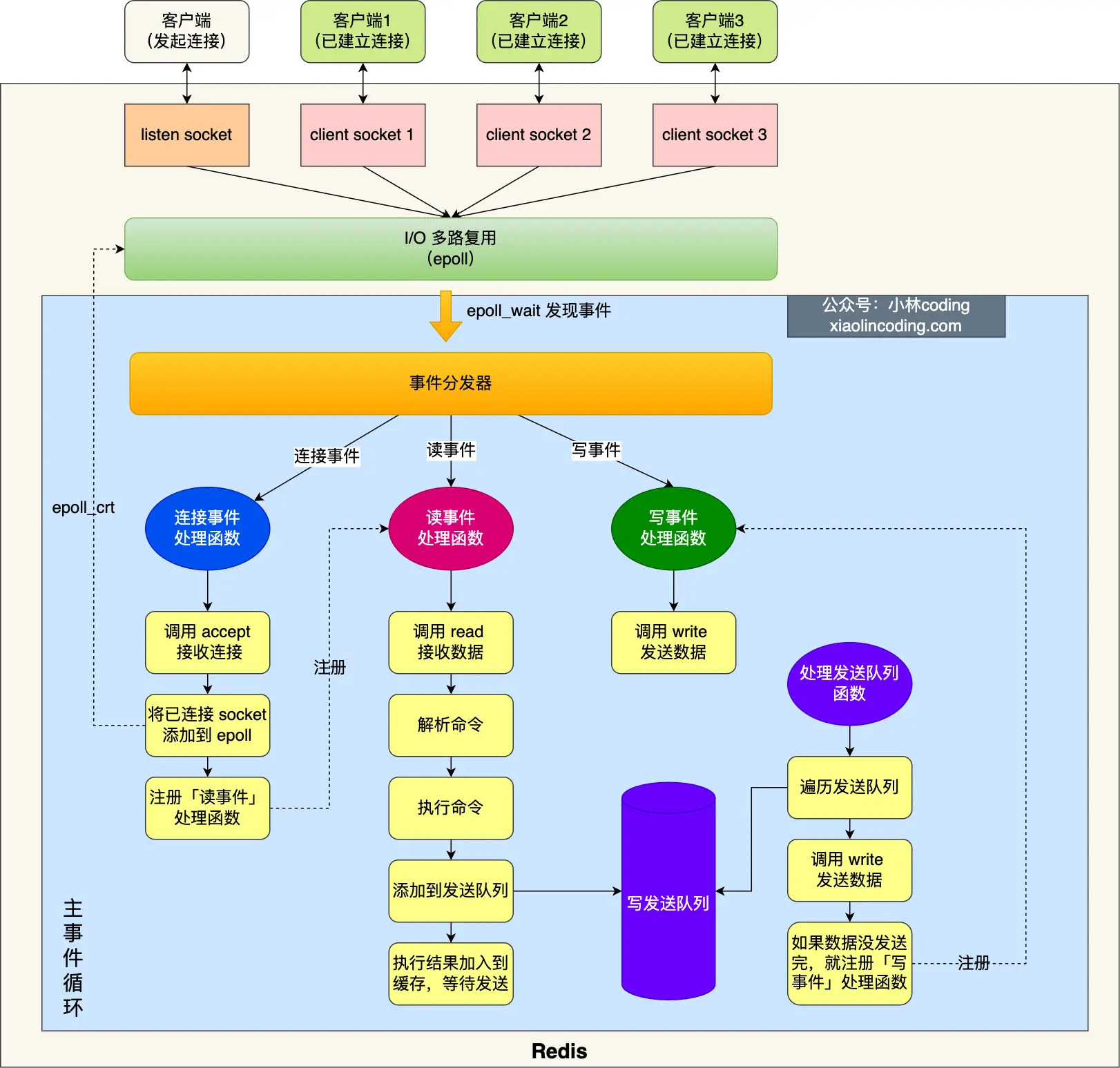
Redis 初始化的时候,会做下面这几件事情:
- 首先,调用 epoll_create() 创建一个 epoll 对象和调用 socket() 创建一个服务端 socket
- 然后,调用 bind() 绑定服务端IP、端口和调用 listen() 服务端开始监听该端口;
- 然后,将调用 epoll_ctl() 将 listen socket 加入到 epoll,同时注册「连接事件」处理函数。
初始化完后,主线程就进入到一个事件循环函数,主要会做以下事情:
-
首先,先调用处理发送队列函数,看是发送队列里是否有任务,如果有发送任务,则通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
-
接着,调用 epoll_wait 函数等待事件的到来:
○如果是连接事件到来,则会调用连接事件处理函数,该函数会做这些事情:调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入到 epoll -> 注册「读事件」处理函数;
○如果是读事件到来,则会调用读事件处理函数,该函数会做这些事情:调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送;
○如果是写事件到来,则会调用写事件处理函数,该函数会做这些事情:通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会继续注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
什么是I/O多路复用模型?
基于TCP协议的Socket通信
客户端与服务端之间要进行通信,最基本的网络I/O模型就是通过socket进行TCP协议通信,流程如下:
- 服务端调用socket()函数,创建一个监听请求的socket,
- 服务端调用bind()函数,在此监听socket上,绑定服务端的IP、应用程序的端口号
- 这是为了让服务端的内核能够收到客户端发来的请求数据,并且发送到相应的应用程序
- 服务端调用listen()函数,开始监听端口,客户端通过调用connect()函数,绑定服务端的IP、端口号,进行TCP三次握手.握手成功后,会将已完成连接的socket,放入服务端内核的TCP全连接队列中
- 服务端通过调用accept()函数,从内核获取已完成连接的socket进行通信,若TCP全连接队列中,无已完成连接的socket,那么就会阻塞等待客户端连接的到来
基于TCP协议的socket通信,是同步阻塞的,当服务端还没处理完一个客户端的网络 I/O ,或者读写操作发生阻塞,其他客户端是无法与服务端连接的,即服务端只能与客户端进行一对一连接通信,一个服务端只能服务一个客户,很低效
基于多进程模型改进网络I/O
要想实现服务端同时服务多个客户端,最原始的方式就是用多进程,即为每一个客户端分配一个进程来处理请求。每当服务端与客户端完成连接,调用accept()函数返回一个已完成连接的socket,主进程就会通过fork()调用,产生一个子进程,与客户端进行通信
这样虽然解决了只能服务于一个客户端的问题,但是因为每产生一个进程,必会占据一定的系统资源,而且进程间上下文切换的代价很大,性能大打折扣。
基于多线程模型改进网络I/O
改进多进程代价高的缺点,使用多线程模型来服务于客户端
线程是运行在进程的执行流,所以可以共享进程的很多资源,对于一些私有数据,才需要进行线程上下文切换,减少了很多开销。
通过线程池,来避免频繁的创建线程,销毁线程。提高性能
但是还不够完美,因为本质上,客户端与服务端的通信,还是基于一对一的方式,只不过模型缩小为线程,能不能让一个进程同时与多个socket进行通信呢?
引入I/O多路复用模型
一个进程,可以维护多个已完成连接的socket
进程怎么知道,哪个socket有事件请求呢?
内核提供了三个系统调用函数,select()/poll()/epoll(),用户态的进程通过调用这些函数,就可以得知,哪些socket有事件请求。
select()/poll():
本质都是在用户态线性存储socket文件描述符集合,当调用函数select()/poll()时,会将存储的集合拷贝到内核,内核通过遍历判断,哪些socket有事件请求,具体分为读/写事件,进行相应的标记。
内核标记完成后,将集合拷贝回用户态,用户态通过遍历的方式,查看哪些文件描述符被标记,进而得知哪些socket有事件请求,具体分为读/写事件,进行相应的处理。
缺点:
对于 select()/poll() 方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一次是在用户态里,还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核标记后,再传出到用户空间中。
显而易见,随着并发数量提示,拷贝 & 遍历 产生的性能消耗,将会非常大。
epoll():
epoll()函数,不同于以上两个系统调用函数的地方在于: 在内核中会用红黑树结构,保存进程维护的socket文件描述符集合,即将已完成连接的socket,通过epoll_ctl() 函数加入内核中的红黑树里, 红黑树进行查找、添加、删除的时间复杂度都为log(N),性能好
并且在内核中,会维护一个有事件发生的socket链表,用户态进程通过epoll_wait()函数,即可得到有事件发生的socket,节省了用户态与内核态进行遍历的过程,提升性能
采用 epoll 模型进行网络I/O,被称为解决 C10K 问题的利器:
支持一个进程打开大数目的socket描述符(FD),它所支持的FD上限是最大可以打开文件的数目
IO效率不随FD数目增加而线性下降, select/poll每次调用都会线性轮询扫描全部的fd集合,导致效率呈现线性下降。epoll不存在这个问题,它只会对活跃的socket进行操作,这是因为在内核实现中epoll是根据每个fd上面的回调函数实现的



