数据库分库分表
数据库分库分表
分库分表到底是什么
分库分表其实是分库,分表,分库分表的总称
分库
将数据按照一定规则存储到不同的数据库中,每个数据库存储一部分数据
分库主要解决的是并发量过大的问题,并发量一旦上升,那么数据库就可能成为系统的瓶颈,因为数据库的连接数量是有上限的,虽然可以进行调整,但并不是无限调整的。所以,当数据库的读或者写的 QPS(每秒查询数) 太高,从而导致你的数据库连接数量不足的时候,就需要考虑到分库了,通过在增加数据库实例的方式来提供更多的数据库连接,从而提升系统的并发度。
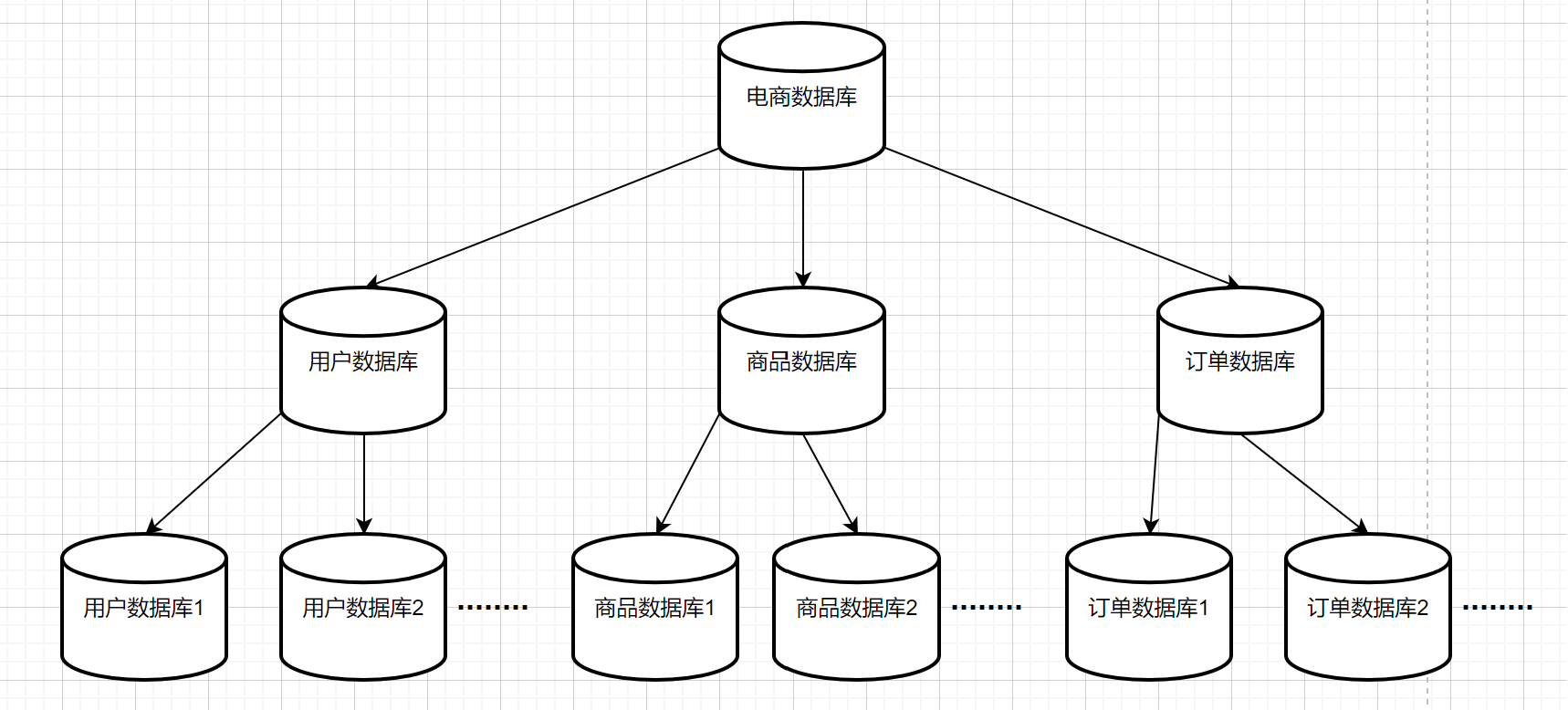
这里拿一个电商系统的数据库来举例,当你微服务在做服务拆分的时候,你会按照功能模块去把你的系统进行服务拆分,这个时候,就需要将每个模块的数据从一个单独的数据库中拆开,分成订单、物流、商品、用户等多个数据库,然后随着业务的发展,每个单独的业务数据库也需要进行分库了,如下图所是。
分表
将一张表按照一定规则拆分成多张表,每张表存储一部分数据
相比较于分库,分表主要解决的是数据量大的问题,即通过将数据拆分到多个表,减少单表的数据量,从而提升查询速度。
分库分表
这一般发生在数据库连接不够(分库解决的问题)以及单表数据量过大导致查询速度比较慢(分表解决的问题)这两个问题共同存在的时候,不过在分库分表之前,可以先考虑一下能不能优化先。
一般来说,单表的行数如果超过了 1000 万行之后,就需要考虑做分库分表了,小于这个数据量的时候,遇到性能问题可以通过其他方式来进行优化。但其实这么说是不准确的,需要根据表字段数量、表中数据数量以及业务的具体情况来综合考虑,无法给出一个确切的值.
- 常⻅的优化手段
- 数据库的基本优化:做好索引、减少多表 join、减少冗余字段
- 减少数据库压力:在数据库之前加一层缓存,把一些可以接受延迟的,以及数据库变化频率较低的内容放到本地缓存或者分布式缓存当中。
- 冷热数据的隔离:即数据归档,可以将一些更新以及不经常使用的数据单独隔离出来,可以放到历史表或者离线数仓当中,减少表中的数据量来提升效率
- 数据库分区:数据库分区之后,将数据存储在不同的表当中,尽量减少单表的数据量,提升查询性能。
- 分布式数据库:将数据分散到多个节点上,提升容量
分区和分表的区别
我们上面提过一个点,就是在数据库中,如果数据量比较大的话,优先考虑的是如何对数据进行优化,而不是进行分库分表,我们在优化里面提到了一个点,就是对数据实现分区操作,那么这个过程要怎么理解呢?以及这两个过程有什么区别?
首先我们先说一个点,就是分区和分表相同的点,都是按照一定的规则,对一张数据量特别大的表进行分解,使得表的数据量减少,从而提高查询效率。这样听起来你可能感觉没差多少,因为两者的区别都是把表进行拆分,那具体有什么差别吗?主要就是分区和分表后数据的存储方式发生了变化。
这个要从 MySQL 的索引说起,在 Innodb 中(8.0之前),表存储主要依赖两个文件,分别是 .frm 文件和.ibd 文件。.frm文件用于存储表结构定义信息,而.ibd文件则用于存储表数据。
拿order表来举例,分区存储时会在 MySQL 的 data 目录下创建一个用户名+表名+分区名.ibd 的文件(如:order_p1.ibd),用来存储 order 表中第一个分区的数据,同样会有 order_p2.ibd 和order_p3.ibd 来存储第二和第三个分区的数据:
1 | order_p1.ibd |
分表存储的时候会在 MySQL 的 Data 目录下创建一个后缀为 .frm,名字为"order_1.frm"的表格文件,存储 order表中第一个分表的数据,同样会有另外的 order_2.frm 和order_3.frm 来存储第二个和第三个分表的数据:
1 | order_1.ibd |
所以简单来说,两者的区别是:
- 数据在做了分区后,表面是还是只有一张表,只不过数据保存在不同的位置上了(同一个.frm文件),在做数据读取的时候操作的表名还是users表,数据库会自己去组织各个分区的数据。
- 数据在进行了分表后,不管是表面上还是实际上,都已经不是同一张表了,其分成了多张表(多个.frm 文件 )。所以数据库在进行操作的时候需要去指定对应的表名
如何分库分表
分库和分表都有两种拆分方式,一种是垂直拆分,一种是水平拆分。
垂直拆分
垂直拆分就是通过将数据库表中的字段减少,然后数据的行数不变,列数减少,来使得每个表中的数据量下降.比如之前提到的电商数据库,将其拆分为订单数据库,商品数据库,用户数据库等,这就属于垂直拆分.如果将用户表常用信息分为用户主表,不常用信息分为用户扩展表,就是表的垂直拆分.垂直拆分主要是根据业务来决定的,不同的业务有着不同的拆分方案.
水平拆分
水平拆分就是将数据库中的表数据分散到多个表中,即数据表中列数不变,行数减少,来使得每个表中的数据量下降.水平拆分的关键在于分片键的选择,分片键是用于将数据库(表)水平拆分的数据库字段,它直接影响了分库分表的性能和可扩展性。以下是一些选择分片键的关键因素:
- 选择一个
尽量均匀的分片键,这样可以使得数据尽量均匀的分布到各个数据库中,避免出现热点数据集中在某个分片上的情况。 - 选择一个
尽量唯一的分片键,这样可以避免数据重复,提高数据的唯一性。 - 选择一个
尽量不变的分片键,这样可以避免对拆分结果的多次修改,提高系统的稳定性和可维护性。 - 选择分片键还应考虑数据的访问频率。将经常访问的数据放在同一个分片上,可以提高查询性能和降低跨分片查询的开销。
常见的水平拆分算法
哈希取模(HASH_MOD)
这是最常用的水平拆分算法,它通过将分片键的哈希值对分片数量取模,来确定数据应该存储的分片。哈希值可能出现负数,要先对其求绝对值之后再取模,下面是ShardingSphere中HASH_MOD算法的实现:
1 | public final class HashModShardingAlgorithm implements StandardShardingAlgorithm<Comparable<?>>, ShardingAutoTableAlgorithm { |
一致性哈希算法
我们在做分库分表的时候,最开始根据业务分析,只需要 128 张表就可以满足数据量的要求了,但是随着业务的扩展,128 张表可能已经不够用了,这个时候就需要重新分表了,比如增加一张新的表,这个时候如果采用 Hash取模的方式,就会导致 128 + 1 张表的数据需要重新进行分配,成本非常高。而一致性哈希算法就是专门解决这类问题的算法,其可以有效地解决分布式系统中增加或者删除节点时的失效问题。
实现一致性哈希算法首先需要构造一个哈希环,然后划分固定数量的虚拟节点,一般都是 2的32次方。接下来将128张表作为节点映射到这些虚拟节点上,每个节点在哈希环上面都有一个对应的虚拟节点。然后我们就需要存储数据了,现在我们要把分片键也根据同样的算法进行 Hash,并且也将其映射到哈希环上面。经过以上步骤,在这个 Hash 环上面的虚拟节点就包含两部分数据的映射了,一部分是存储数据的分表的映射,一部分是真实要存储的数据的映射。
我们最终目的是将这些数据存储到数据库分表中,那么做好哈希之后,这些数据又要保存在哪个数据库表节点中呢?这个其实很简单,就是按照数据的位置,沿着顺时针的方向进行查找,找到的第一个数据库表节点就是数据要存放的数据库表节点。
回到开头的问题,我们要添加第129张表,只要将第129张表的虚拟节点映射到哈希环上,然后将数据重新分配即可,这样只会影响到哈希环上新增节点顺时针旋转的下一个节点的数据,而不会影响到其他节点。
一致性哈希算法的优缺点:
优点:
- 数据均衡:在增加或者删除节点的时候,一致性哈希算法只会影响到少量的数据迁移,保持了数据的均衡性。
- 高扩展性:当节点数目发生变化的时候,对于已经存在的数据,只有部分数据需要重新分布,不会影响到整体的数据结构。
缺点:
- Hash 倾斜:在节点数较少的情况下,由于哈希空间是有限的,节点的分布可能不够均匀,导致数据倾斜。
- 节点的频繁变更: 如果频繁添加或删除节点,可能会导致大量的数据迁移,从而造成系统压力。
Hash 倾斜的解决方案:
-
力大砖飞,增加节点,尽可能地分散节点,使得数据分布较为均匀,但这不太现实,因为有这个条件也就不会出现 Hash 倾斜的问题了。
-
引入虚拟节点,即我们将一个服务器节点拆分成多个虚拟节点,然后数据在映射的时候先将数据映射到虚拟节点上,然后虚拟节点在对应的物理节点进行存储和读取就可以了,有了虚拟节点的接入,数据在分布的时候就会尽可能地分散,然后在增加或者减少服务器数量的时候,受到影响的数据范围也不会有那么多。
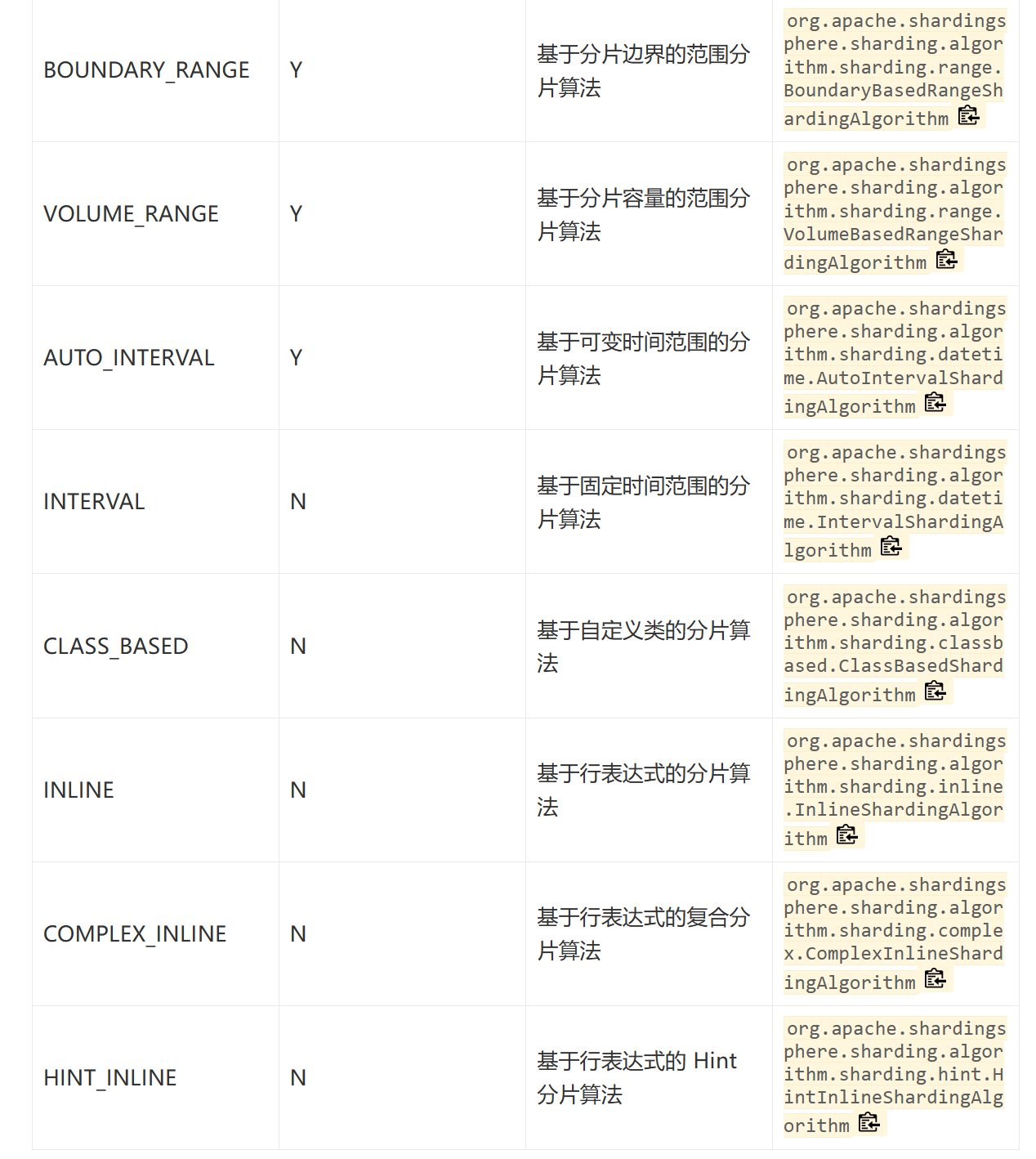
其他算法
ShardingSphere的分片算法还有如下图这些:
分表之后的全局 ID 如何保证全局唯一性?
我们在单表中可以采用数据库主键来做唯一的 ID,但是如果使用了分库分表的形式,那么多张单表中的自增主键就一定会发生冲突,那这样的话你生成的ID 就不具备全局唯一性了
UUID
UUID是可以做到全局唯一性的,而且生成方式也很简单,而且性能很高,不依赖于网络,使用起来也比较方便。但是我们通常不使用他作为唯一 ID,主要原因有两个:
- UUID 太⻓了,它有 32 位 16进制的数字,且字符串的查询效率也比较慢,在作为分布式 ID 查询的时候存在查询效率较低,不适合范围查询以及不方便展示等问题。
- 不具有业务性,标准的 UUID 格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12),一共32个字符,这个时候我们随便举一个例子,“340a3413-b8a2-c1e6-f922-895398142390”,对于这个字符串来说,很难看出其表达的含义,如果使用其作为全局唯一标识,在分布式系统中,很难进行问题的排查以及开发过程中的调试,所以我们一般不考虑 UUID 作为全局唯一标识
基于某个单表做自增主键
利用一个表来存放自增 ID ,然后所有的表在需要主键的时候来这张表里面取就可以了,这样做就可以实现全局唯一,还实现了自增效果,一举两得。这样不否定,确实可以实现全局唯一而且还能实现自增效果,但是有一个问题,就是这张单表最终会成为了系统扩展的瓶颈,而且也存在单点问题,一旦这张表有一天突然挂了,那整个数据库的插入不就瘫痪了吗?
基于多个单表+步⻓做自增主键
设置起始值和步长,比如table_001起始值为10000,步长为10000,其范围就为10000-19999,table_002起始值为20000,步长为10000,其范围就为20000-29999,以此类推,这样就可以实现全局唯一,而且还能实现自增效果.但是又有了一个新的问题,那就是table_001如果 ID 到了19999 ,这个怎么办?那就重新生成一个起始值:table_001的新起始值为80000,其范围为80000-89999,以此类推.
雪花算法
雪花算法是一种比较常⻅的分布式 ID 的生成方式,它具有全局唯一、递增、高可用的特点。它的核心思想就是将一个 64位的ID划分成多个部分,每个部分都有不同的含义,包括时间戳、数据中心标识、机器标识和序列号等。

一般来说,雪花算法生成的 ID 有以下几个部分:
- 最高1位固定值0,因为生成的 id 是正整数,如果是1就是负数了。
- 接下来41位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用69年。
- 再接下10位存储机器码,包括5位 datacenterId 和5位 workerId。最多可以部署2^10=1024台机器。
- 最后12位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成2^12=4096个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。对于每一个雪花算法服务,需要先指定10位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的10位比特位的整数值都行。
当然雪花算法也有其缺点:依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
像百度,美团等大厂都在github上开源了自己的分布式ID生成器,有兴趣的可以自行了解。
分库分表后的查询
带分片键的查询
由于带有分片键,我们可以定位到具体的库和表,然后进行查询.
不带分片键的关键查询
以电商网站为例,电商网站上不仅有买家,还有卖家,他们的查询也很高频,该怎么做呢?针对卖家查询,一般会采用空间换时间的方案,同步出一张按照卖家维度做分表的表来。虽然这种情况下可能存在秒级的延迟,但是一般业务上来说都是可以接受的。也就是说,当一条订单创建出来之后,会在买家表创建一条记录,以买家ID作为分表字段,同时,也会在卖家表创建一条记录出来,用卖家ID进行分表。并且这张卖家表不会做任何写操作,只提供查询服务,完全可以用一些比较廉价的机子去部署数据库实例。这样,卖家的分⻚等查询就可以直连卖家表做查询了。
不带分片键的聚合查询
一般来说,大厂用的比较多的方案就是使用分布式数据仓库来实现,也就是说我们会把这些数据同步到像TiDB、PolarDB、HBase等这些数据库中,或者同步到ES中,然后在这些数据库中做数据的聚合查询。