美赛C题学习
美赛C题学习
如果自建模型,可以参考2218931的4.2.1,2218931的论文描述值得学习,最后的信也比较有特色
跟现实相结合也是很重要的点,最好能有案例支撑,虽然说在C题中不常见,但其实有的地方也可以加上
时间序列预测
可以关注一些特殊的时间节点,比如节假日,季节性,节假日和季节性都有可能影响时间序列的预测。
-
ARIMA:经典时间序列预测模型,使用自回归积分移动平均模型,该模型可以对时间序列数据进行预测,并且可以对时间序列数据进行平滑处理,可以参考下2203120的写法。
-
GRU:时间序列预测,和LSTM类似,但是GRU的更新门和遗忘门合并为更新门,输入门和输出门合并为输出门,所以GRU的参数更少,更便于计算.
-
SIR:SIR模型,用于传染病传播的预测,S表示易感者,I表示感染者,R表示康复者,也适用于某些突然爆火的事件。
-
Prophet:时间序列预测,使用Facebook的Prophet算法,该算法基于时间序列历史数据,拟合出一个趋势和季节性,然后预测未来的时间序列。参考2301192,2200688
-
卡尔曼滤波算法
-
LightGBM:LightGBM是一种基于梯度提升决策树的机器学习算法,它具有高效性、可扩展性和可解释性等特点。在时间序列预测任务中,LightGBM可以有效地处理大量数据,并生成可解释的预测结果。
-
XGBoost:XGBoost是一种基于梯度提升决策树的机器学习算法,它具有高效性、可扩展性和可解释性等特点。
-
LSTM:长短期记忆网络(Long Short-Term Memory,LSTM)是一种循环神经网络(RNN)的变体,它能够有效地处理时间序列数据。LSTM通过引入记忆单元和门机制,能够有效地捕捉和传递时间序列数据中的长期依赖关系。可与参考下2204883
-
ARIMA-LSTM:这两个模型结合感觉还是不错的,2212336,把LSTM换成GRU也是差不多的效果
-
ARIMA-SVM:来自2100948,可能参考了
https://blog.csdn.net/u014356002/article/details/53163684,SVM和LSTM都用来捕捉非线性部分,但在预测上SVM不如LSTM,但SVM可解释性相对更好
多模型堆叠:可以参考一下这里面的https://blog.csdn.net/keypig_zz/article/details/82819558,这个图和流程可以参考
非时间序列预测
-
GSRF:网格搜索的随机森林算法
-
维特比算法:主要用于解决隐马尔可夫模型(HMM)中的状态序列预测问题。在语音识别、自然语言处理、生物信息学等领域中,维特比算法被用于根据观测序列预测最有可能的状态序列。
-
MMOE模型:是一种多任务学习架构,旨在提高模型在处理多个相关任务时的性能。该模型由谷歌在2018年的KDD会议上提出,并因其有效的参数共享机制和任务特定处理能力而被业界广泛采用。来源于2307946,其用于预测尝试次数百分比.
-
多元线性回归:用于预测多个自变量对因变量的影响。
聚类算法(分类)
-
k-means:k-means聚类算法,人为决定初始聚类中心,较为主观,可改用k-means++,或者使用Gap Statistic方法确定最佳k值
-
k-means++:k-means++聚类算法
-
DBSCAN:DBSCAN聚类算法
-
BIRCH:BIRCH聚类算法
-
GMM:GMM聚类算法,聚类效果比kmeans好,如果后续要降维,可以考虑使用kmeans++
-
谱聚类:谱聚类算法
-
层次聚类:层次聚类算法
-
R-CNN家族: R-CNN , Fast R-CNN , Faster R-CNN , Mask R-CNN,物体检测算法,在2106138中用于分类大黄蜂和胡蜂
其他
数据处理流程建议参考一下2208834
模型最好都要有训练集和测试集,训练集和测试集最好要分开,训练集和测试集最好要随机打乱,这样模型才能有更好的效果。测试集可以从已有数据中随机抽取一部分作为测试集,也可以从训练集中划分一部分作为测试集。训练集和测试集的比例可以根据实际情况进行调整,一般来说,训练集的比例要大于测试集的比例。
影响因子最好保留5-8个,如果影响因子太多,模型可能会过拟合,如果影响因子太少,模型可能会欠拟合。最好是从多个影响因子中挑选出来.
步骤如下:
- 数据收集、数据清洗、数据标准化
- 相关性分析,分析各因子之间的相关性。高度相关的因子可能代表相似的信息,可以考虑合并或只保留一个。
- 使用PCA(主成分分析法)进行降维,选择最重要的5-8个影响因子.
- 确定权重:使用层次分析法、熵权法、主成分分析法、变异系数法等方法确定权重.
白噪声测试: 白噪声测试是用来检验时间序列数据是否为随机游走的,如果时间序列数据是随机游走的,那么它应该具有均匀的分布。白噪声测试可以使用ADF(Augmented Dickey-Fuller)检验方法来判断时间序列数据是否为随机游走。如果ADF检验结果的p值小于0.05,那么时间序列数据就不是随机游走的。
-
ADF测试:是一种统计检验方法,用于确定一个时间序列数据是否平稳。在经济学和金融学中,时间序列数据的平稳性是一个重要的概念,因为它有助于预测未来的经济活动。如果一个时间序列是平稳的,那么它的统计特性(如均值、方差和自协方差)不会随时间变化。如果数据平稳,可以使用原始数据,如果不平稳,则要对数据进行处理.具体方案如下:
-
差分:如果数据是非平稳的,通过对数据进行一阶或更高阶的差分,可以去除数据中的趋势、季节性或其他时间动态特征,从而使数据变得平稳。差分是一种常见的时间序列平稳化技术。
-
季节性调整:对于具有季节性波动的数据,可以通过季节性调整来去除季节性因素,使数据更加平稳。这可以通过移动平均、季节性分解时间序列预测(STL)等方法来实现。
-
漂白:漂白是一种统计技术,通过它可以从时间序列中去除长期趋势和季节性成分,只保留短期波动。这可以通过自回归模型(如AR模型)来实现。
-
Box-Cox变换:这是一种用于处理非正态分布数据的技术,通过变换可以将数据转换为正态分布,有时这也有助于提高数据的平稳性。
-
处理异常值:检查数据中是否存在异常值或离群值,并考虑是否需要将其删除或进行某种形式的调整。
-
使用更高级的模型:有时,使用更高级的经济计量模型(如向量自回归模型VAR或状态空间模型)可以处理非平稳数据,而不需要直接对数据进行平稳化处理。
-
-
CTGAN:生成对抗网络,可用于拓展数据集(谨慎使用)
-
OpenFE:是一种功能强大的特征自动生成算法OpenFE,它能有效地生成有用的特征,提高模型学习性能(GBDT相关模型和SOAT神经网络).
-
Bootstrap方法:通过重复抽样和计算统计量来估计总体的分布,可以用来进行假设检验,置信区间构建,稳健性分析等。论文2309397对预测结果使用Bootstrap方法构建置信区间,取置信水平95%时的结果作为预测区间。
图建议15-20张,表建议3-8个,总数20-25最佳
使用比较高级的模型最好画上原理图,模型进行结合也最好画图表示一下.如果建立的模型比较简单,那就得在分析和图像上下功夫.每一个task的分析至少得有一张图
可以用伪代码去展示一些不好用图表展示的行业性的算法,例如2200401的交易策略
- NSGS-II:多目标优化算法,参考2218743
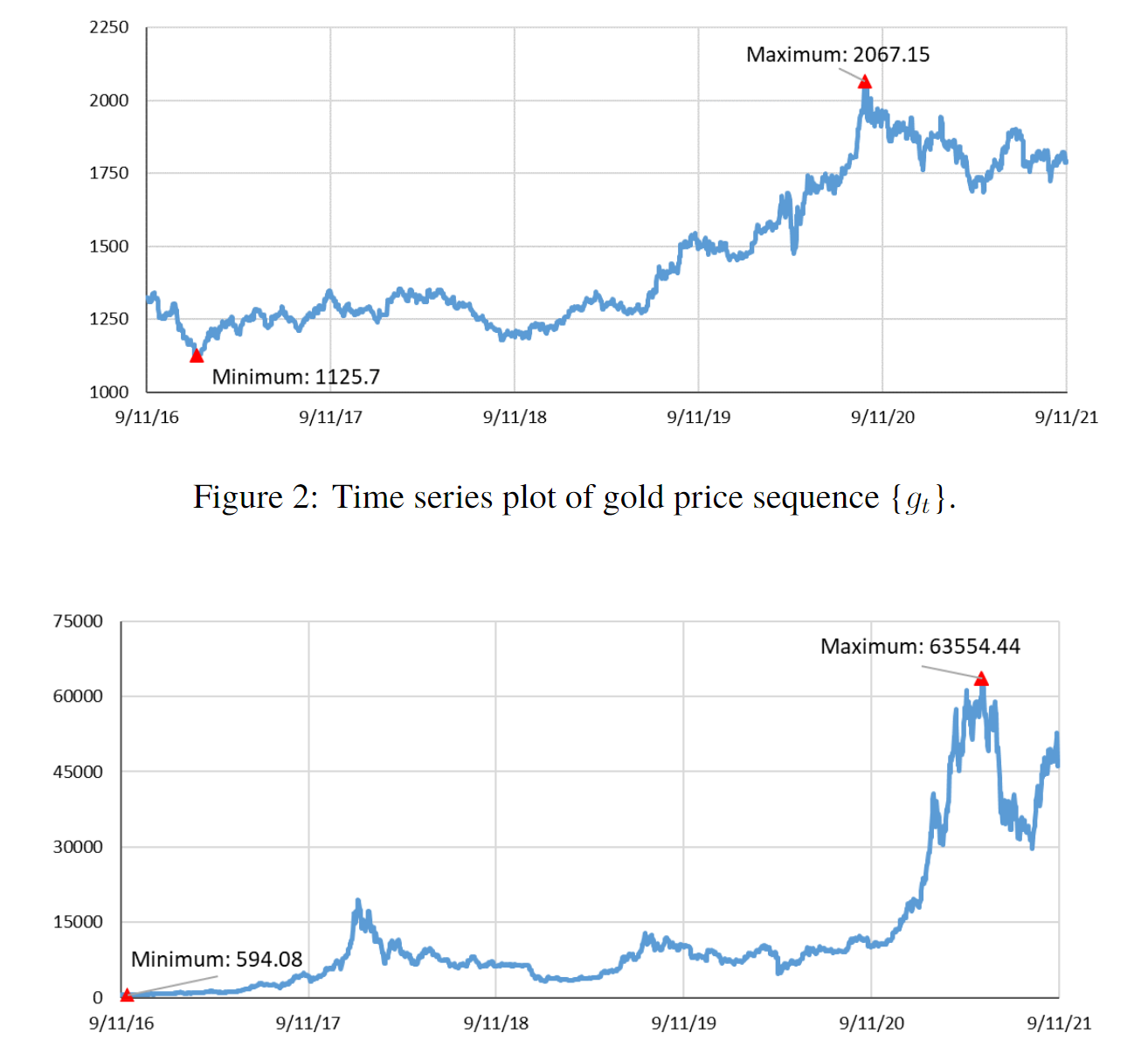
简单的图也可以画得不一样,比如折线图,我们可以将最值标记出来,将异常值标记出等等
词云可视化也可以作为一大亮点
21年的可以看下2107079
