JVM内存区域
JVM内存区域
在传统的C/C++开发中,我们经常通过使用申请内存的方式来创建对象或是存放某些数据,但是这样也带来了一些额外的问题,我们要在何时释放这些内存,怎么才能使得内存的使用最高效,因此,内存管理是一个非常严肃的问题。
比如我们就可以通过C语言malloc函数动态申请内存,并用于存放数据,而在Java中,这种操作实际上是不允许的,Java只支持直接使用基本数据类型和对象类型,至于内存到底如何分配,并不是由我们来处理,而是JVM帮助我们进行控制,这样就帮助我们节省很多内存上的工作,虽然带来了很大的便利,但是,一旦出现内存问题,我们就无法像C/C++那样对所管理的内存进行合理地处理,因为所有的内存操作都是由JVM在进行,只有了解了JVM的内存管理机制,我们才能够在出现内存相关问题时找到解决方案。
内存区域划分
既然要管理内存,那么肯定不会是杂乱无章的,JVM对内存的管理采用的是分区治理,不同的内存区域有着各自的职责所在,在虚拟机运行时,内存区域如下划分:
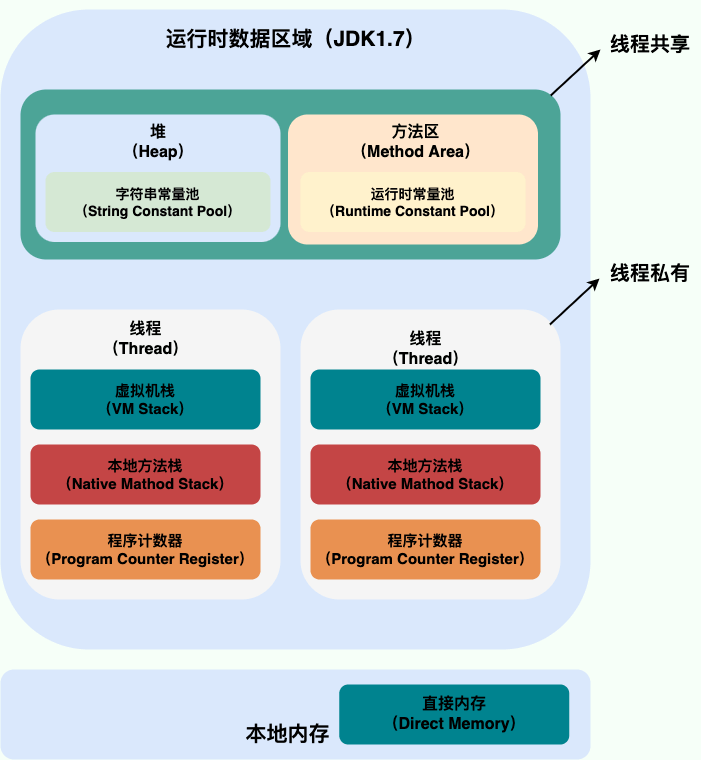
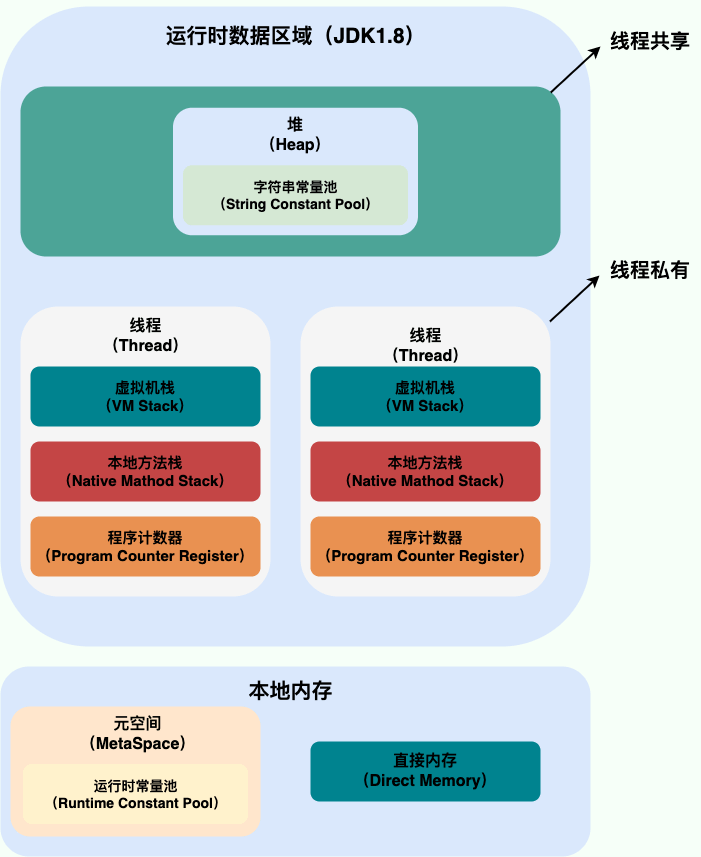
我们可以看到,内存区域一共分为5个区域,其中方法区,堆和直接内存是所有线程共享的区域,随着虚拟机的创建而创建,虚拟机的结束而销毁,而虚拟机栈、本地方法栈、程序计数器都是线程之间相互隔离的,每个线程都有一个自己的区域,并且线程启动时会自动创建,结束之后会自动销毁。内存划分完成之后,我们的JVM执行引擎和本地库接口,也就是Java程序开始运行之后就会根据分区合理地使用对应区域的内存了。
大致划分
程序计数器
首先我们来介绍一下程序计数器,它和我们的传统8086 CPU中PC寄存器的工作差不多,因为JVM虚拟机目的就是实现物理机那样的程序执行。在8086 CPU中,PC作为程序计数器,负责储存内存地址,该地址指向下一条即将执行的指令,每解释执行完一条指令,PC寄存器的值就会自动被更新为下一条指令的地址,进入下一个指令周期时,就会根据当前地址所指向的指令,进行执行。
而JVM中的程序计数器可以看做是当前线程所执行字节码的行号指示器,而行号正好就指的是某一条指令,字节码解释器在工作时也会改变这个值,来指定下一条即将执行的指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
因为Java的多线程也是依靠时间片轮转算法进行的,因此一个CPU同一时间也只会处理一个线程,当某个线程的时间片消耗完成后,会自动切换到下一个线程继续执行,而当前线程的执行位置会被保存到当前线程的程序计数器中,当下次轮转到此线程时,又继续根据之前的执行位置继续向下执行。
为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
程序计数器因为只需要记录很少的信息,所以只占用很少一部分内存。
⚠️ 注意:程序计数器是唯一一个不会出现OutOfMemoryError的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
虚拟机栈
虚拟机栈就是一个非常关键的部分,看名字就知道它是一个栈结构,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(其实就是栈里面的一个元素),栈帧中包括了当前方法的一些信息,比如局部变量表、操作数栈、动态链接、方法出口等。
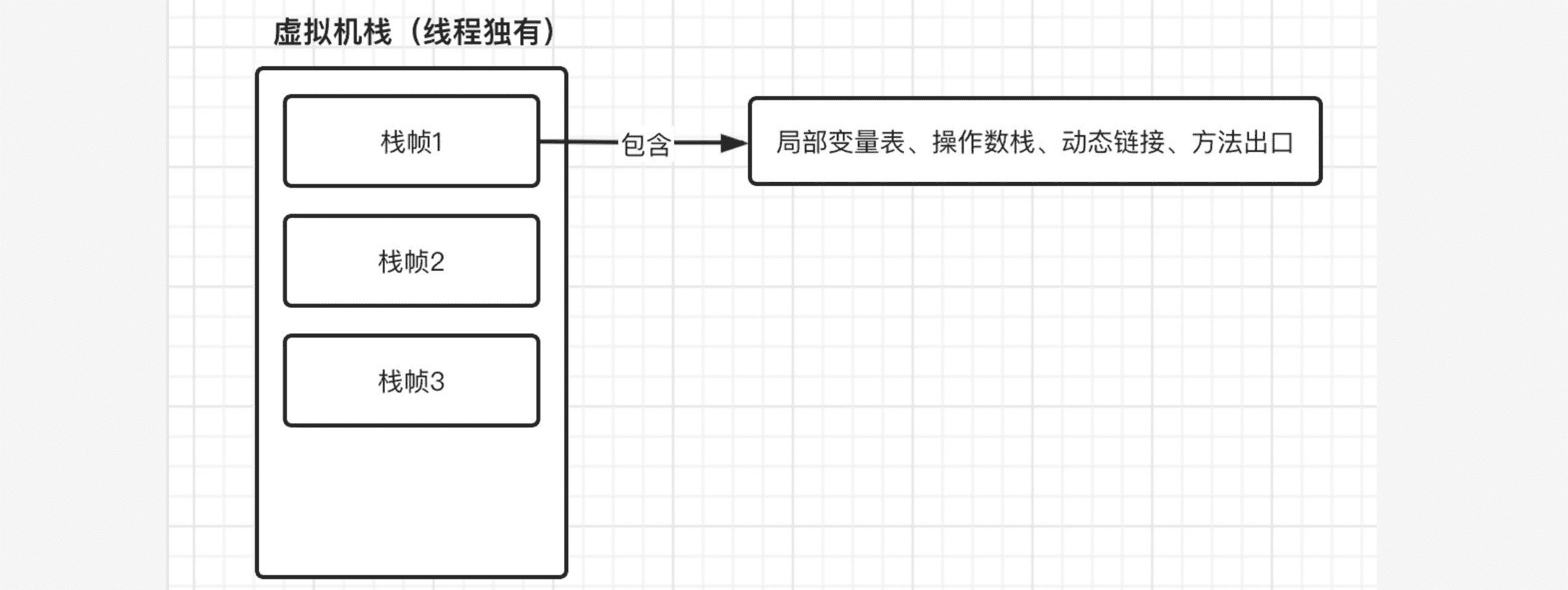
其中局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置),在class文件中就已经定义好了
操作数栈主要作为方法调用的中转站使用,用于存放方法执行过程中产生的中间计算结果。另外,计算过程中产生的临时变量也会放在操作数栈中
每个栈帧还保存了一个可以指向当前方法所在类的运行时常量池,目的是:当前方法中如果需要调用其他方法的时候,能够从运行时常量池中找到对应的符号引用,然后将符号引用转换为直接引用,然后就能直接调用对应方法,这就是动态链接
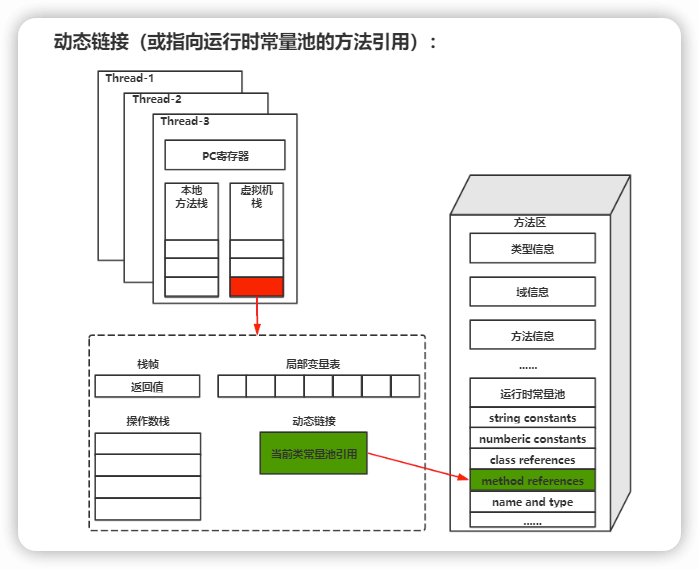
最后是方法出口,也就是方法该如何结束,是抛出异常还是正常返回,不管哪种返回方式,都会导致栈帧被弹出。也就是说, 栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。
程序运行中栈可能会出现两种错误:
- StackOverFlowError: 若栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
- OutOfMemoryError: 如果栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
这里我们来模拟一下整个虚拟机栈的运作流程,我们先编写一个测试类:
1 | public class Main { |
当我们的主方法执行后,会依次执行三个方法a() -> b() -> c() -> 返回,我们首先来观察一下反编译之后的结果:
1 | { |
可以看到在编译之后,我们整个方法的最大操作数栈深度、局部变量表都是已经确定好的,当我们程序开始执行时,会根据这些信息封装为对应的栈帧,我们从main方法开始看起:
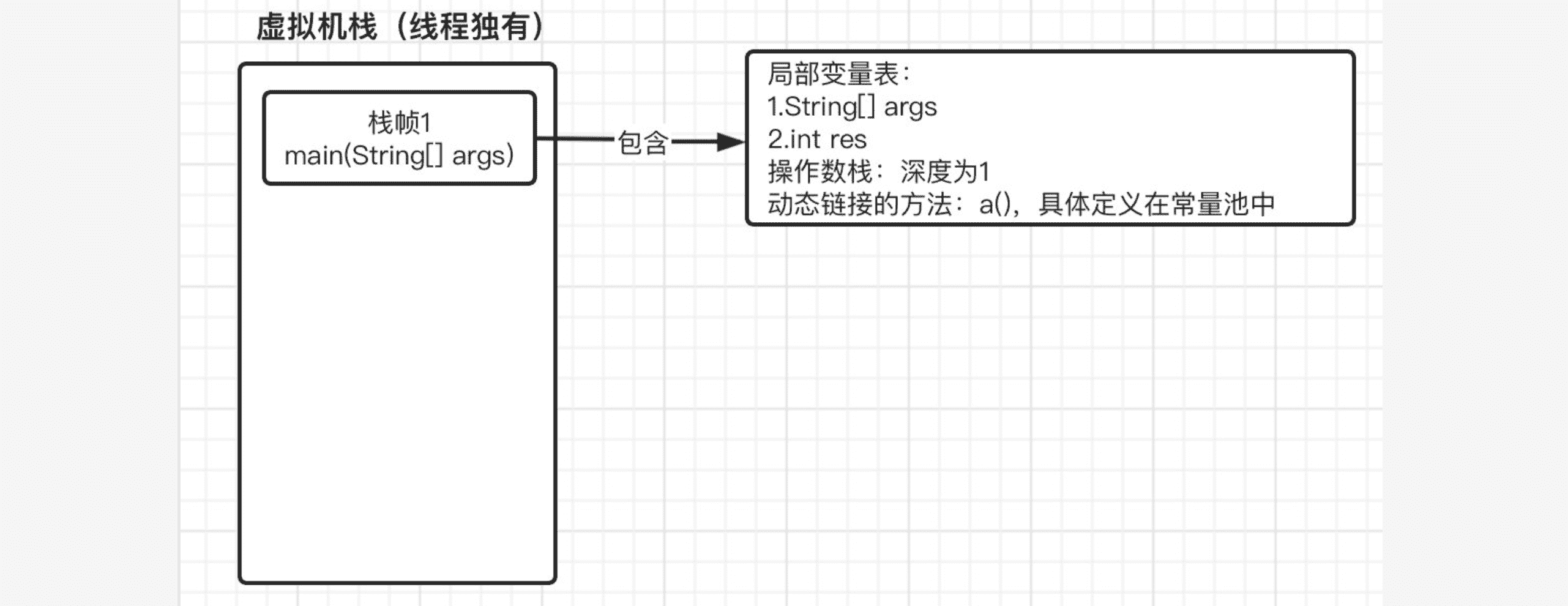
接着我们继续往下,到了 0: invokestatic #2 // Method a:()I时,需要调用方法a(),这时当前方法就不会继续向下运行了,而是去执行方法a(),那么同样的,将此方法也入栈,注意是放入到栈顶位置,main方法的栈帧会被压下去:
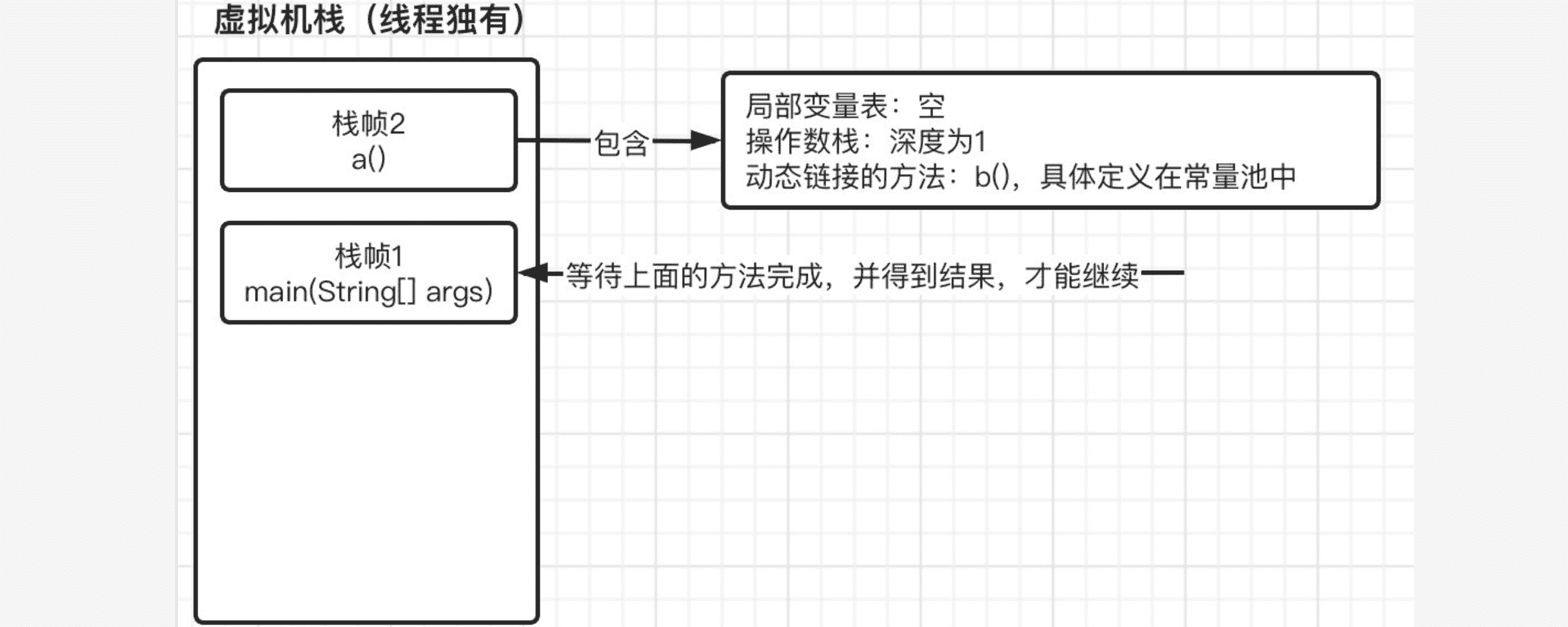
这时,进入方法a之后,又继而进入到方法b,最后在进入c,因此,到达方法c的时候,我们的虚拟机栈变成了:
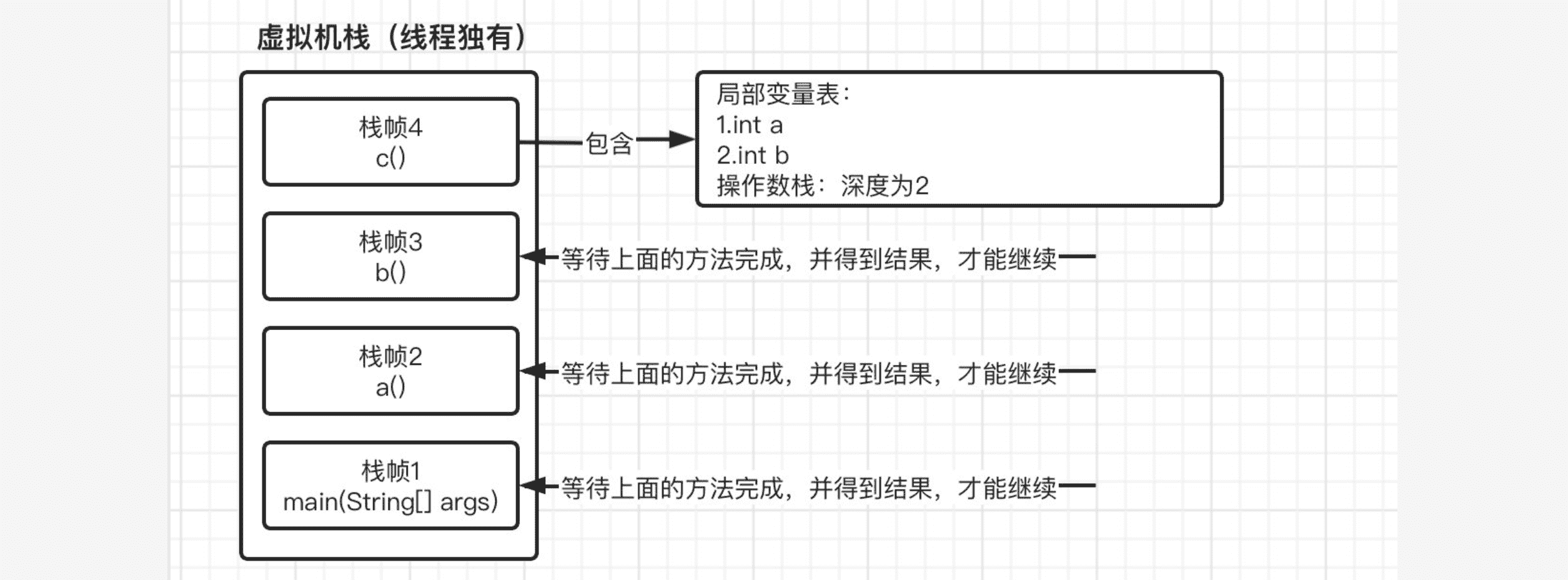
现在我们依次执行方法c中的指令,最后返回a+b的结果,在方法c返回之后,也就代表方法c已经执行结束了,栈帧4会自动出栈,这时栈帧3就得到了上一栈帧返回的结果,并继续执行,但是由于紧接着马上就返回,所以继续重复栈帧4的操作,此时栈帧3也出栈并继续将结果交给下一个栈帧2,最后栈帧2再将结果返回给栈帧1,然后栈帧1就可以继续向下运行了,最后输出结果。
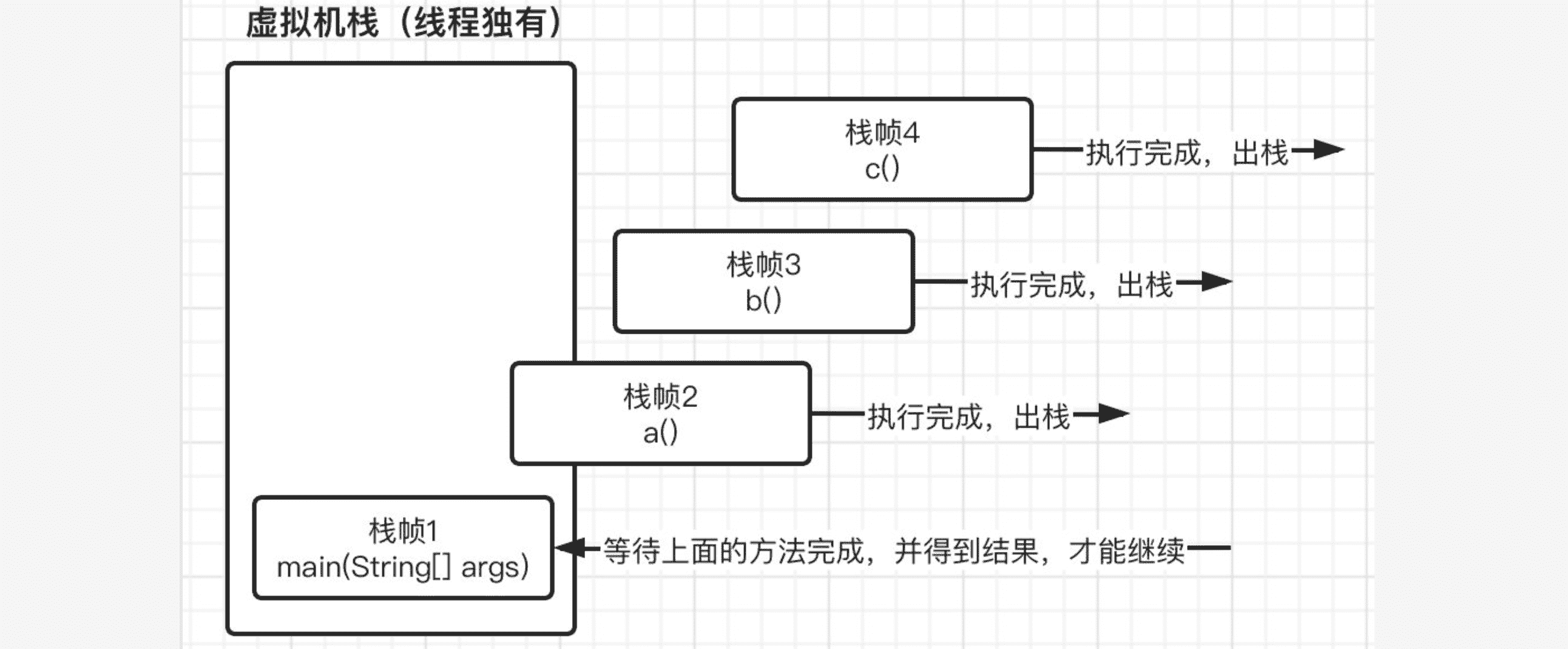
本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是:虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
本地方法栈在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
堆
堆是整个Java应用程序共享的区域,也是整个虚拟机最大的一块内存空间,而此区域的职责就是存放和管理对象和数组。
Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。从 JDK 1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。
Java 堆是垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)。从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden、Survivor、Old 等空间。进一步划分的目的是更好地回收内存,或者更快地分配内存。在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
- 新生代内存(Young Generation)
- 老生代(Old Generation)
- 永久代(Permanent Generation)
下图所示的 Eden 区、两个 Survivor 区 S0 和 S1 都属于新生代,中间一层属于老年代,最下面一层属于永久代。
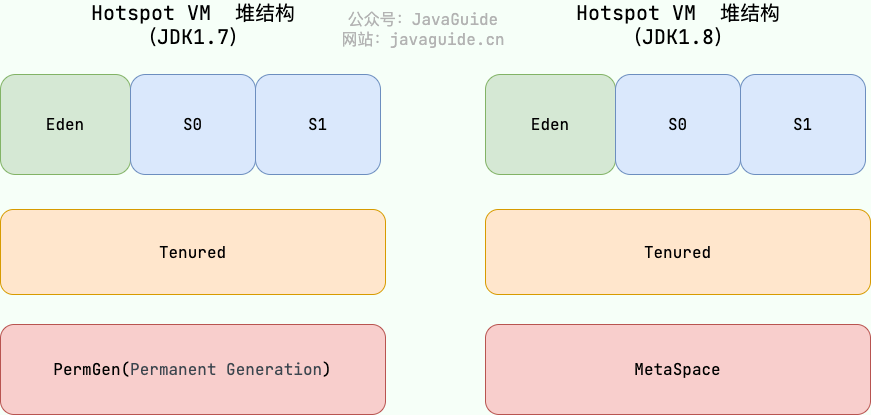
JDK 8 版本之后 PermGen(永久代) 已被 Metaspace(元空间) 取代,元空间使用的是本地内存。
大多数情况下,对象在新生代中 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC(新生代垃圾回收)。在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会变为1(Eden 区->Survivor 区后对象的初始年龄变为 1,每经历一次Minor GC且存活下来,年龄+1)。当年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升到老年代的年龄阈值(长期存活的对象进入老年代)。
大对象直接进入老年代:
对于一个大对象,我们会首先在Eden 尝试创建,如果创建不了,就会触发Minor GC。随后继续尝试在Eden区存放,发现仍然放不下,尝试直接进入老年代,老年代也放不下,触发 Full GC 清理空间,再次放入老年代,如果放不下就报OutOfMemory错误。
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
1. 部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
2. 整堆收集 (Full GC):收集整个 Java 堆和方法区。
- 触发条件1:每次晋升到老年代的对象平均大小大于老年代剩余空间
- 触发条件2:Minor GC后存活的对象超过了老年代剩余空间
- 触发条件3:永久代内存不足(JDK8之前)
- 触发条件4:手动调用
System.gc()方法
堆这里最容易出现的就是 OutOfMemoryError 错误,并且出现这种错误之后的表现形式还会有几种,比如:
- java.lang.OutOfMemoryError: GC Overhead Limit Exceeded:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
- java.lang.OutOfMemoryError: Java heap space :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过-Xmx参数配置,若没有特别配置,将会使用默认值)
方法区
方法区也是整个Java应用程序共享的区域,它用于存储所有的类信息、常量、静态变量、动态编译缓存等数据,可以大致分为两个部分,一个是类信息表,一个是运行时常量池。
方法区和永久代以及元空间是什么关系呢?永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
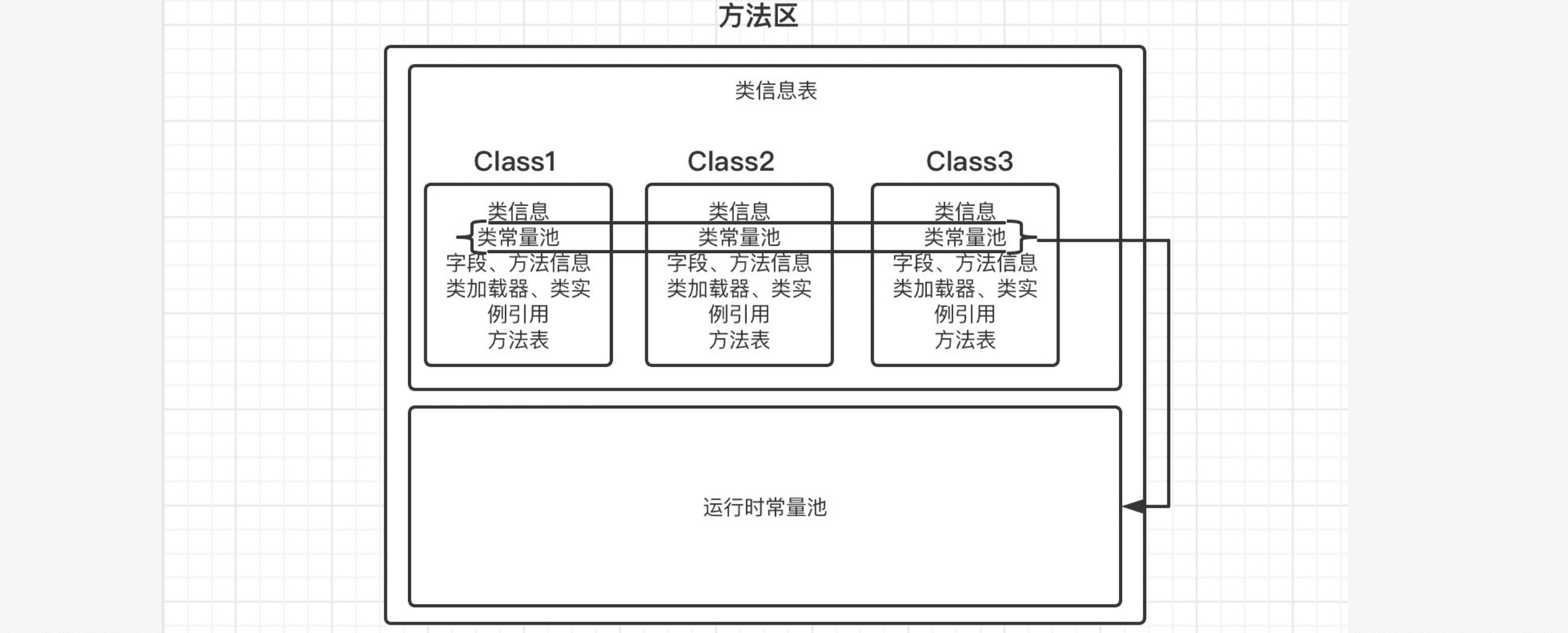
首先类信息表中存放的是当前应用程序加载的所有类信息,包括类的版本、字段、方法、接口等信息,同时会将编译时生成的常量池数据全部存放到运行时常量池中。当然,常量也并不是只能从类信息中获取,在程序运行时,也有可能会有新的常量进入到常量池。
运行时常量池
Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量和符号引用的 常量池表。
常量池表会在类加载后存放到方法区的运行时常量池中。运行时常量池的功能类似于传统编程语言的符号表,尽管它包含了比典型符号表更广泛的数据。
字符串常量池
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
JDK1.7 之前,字符串常量池存放在永久代。JDK1.7 字符串常量池和静态变量从永久代移动了 Java 堆中。
JDK 1.7 为什么要将字符串常量池移动到堆中?
主要是因为永久代(方法区实现)的 GC 回收效率太低,只有在整堆收集 (Full GC)的时候才会被执行 GC。Java 程序中通常会有大量的被创建的字符串等待回收,将字符串常量池放到堆中,能够更高效及时地回收字符串内存。
我们编写一个测试用例:
1 | public static void main(String[] args) { |
得到的结果也是显而易见的,由于str1和str2是单独创建的两个对象,那么这两个对象实际上会在堆中存放,保存在不同的地址:
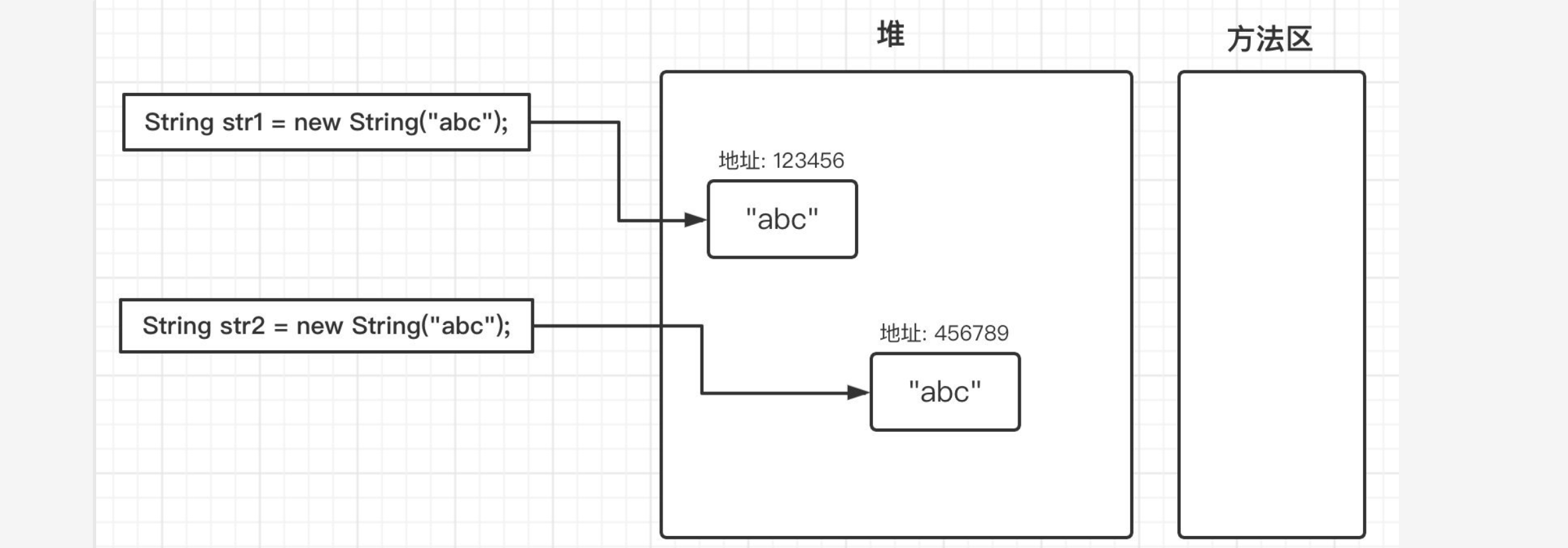
所以当我们使用==判断时,得到的结果false,而使用equals时因为比较的是值,所以得到true。现在我们来稍微修改一下:
1 | public static void main(String[] args) { |
现在我们没有使用new的形式,而是直接使用双引号创建,那么这时得到的结果就变成了两个true,这是为什么呢?这其实是因为我们直接使用双引号赋值,会先在常量池中查找是否存在相同的字符串,若存在,则将引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将引用指向该字符串:
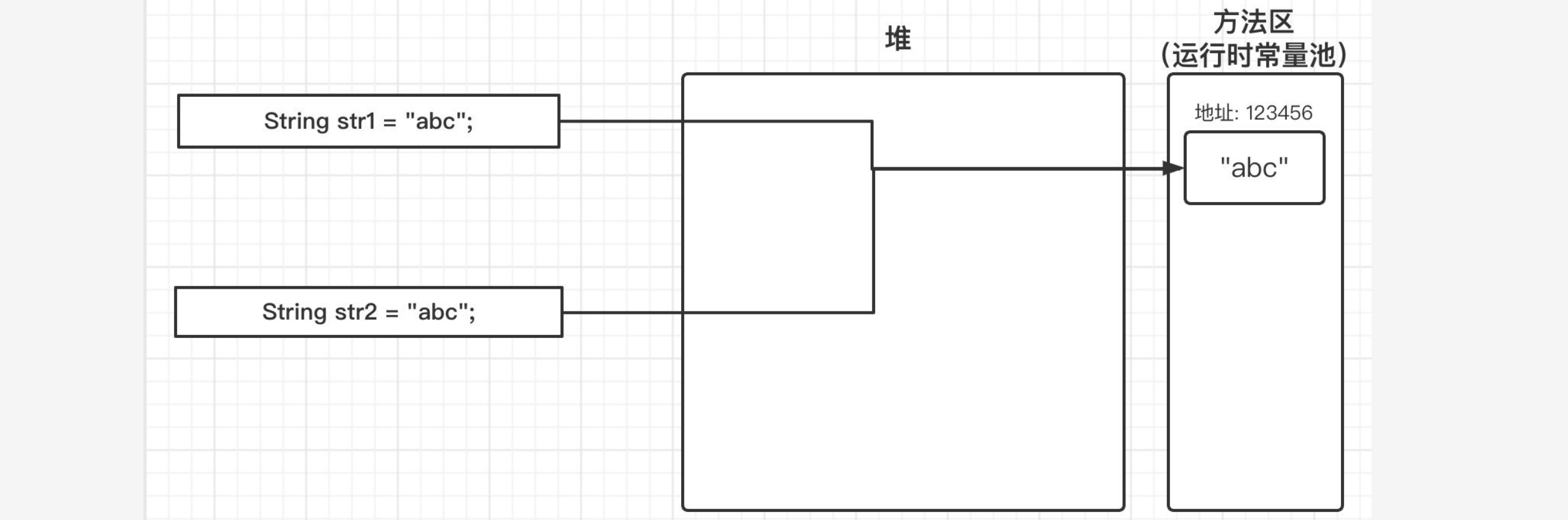
实际上两次调用String类的intern()方法,和上面的效果差不多,也是第一次调用会将堆中字符串复制并放入常量池中,第二次通过此方法获取字符串时,会查看常量池中是否包含,如果包含那么会直接返回常量池中字符串的地址:
1 | public static void main(String[] args) { |
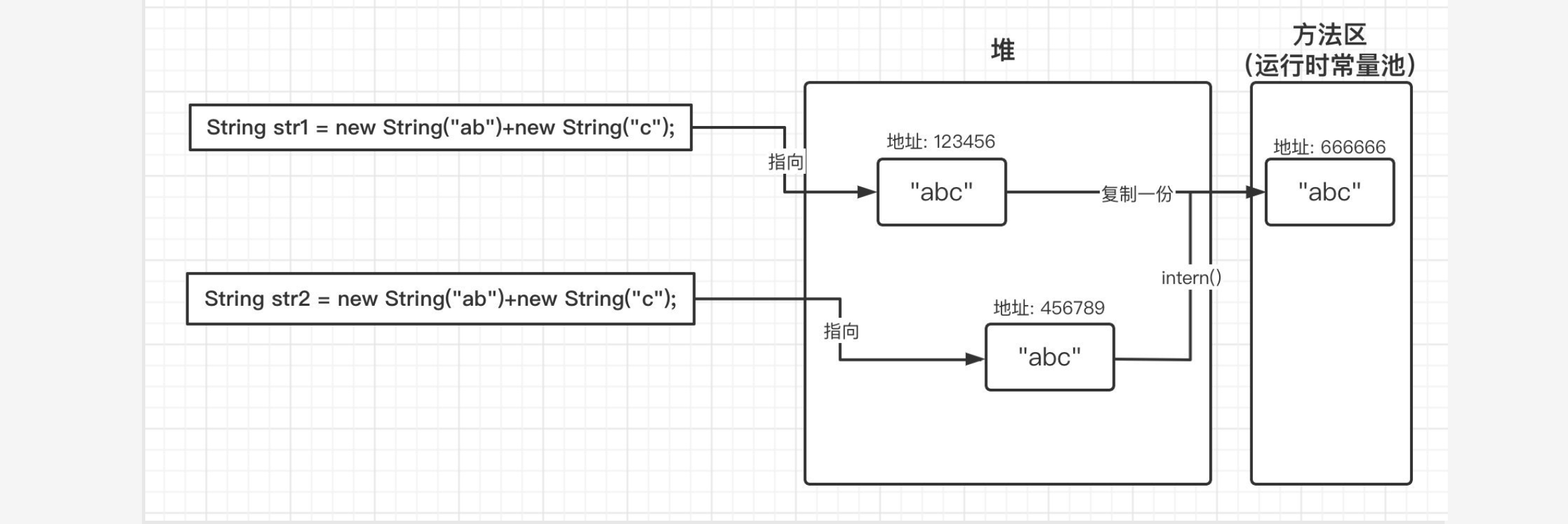
所以上述结果中得到的依然是两个true。在JDK1.7之后,稍微有一些区别,在调用intern()方法时,当常量池中没有对应的字符串时,不会再进行复制操作,而是将其直接修改为指向当前字符串堆中的的引用:
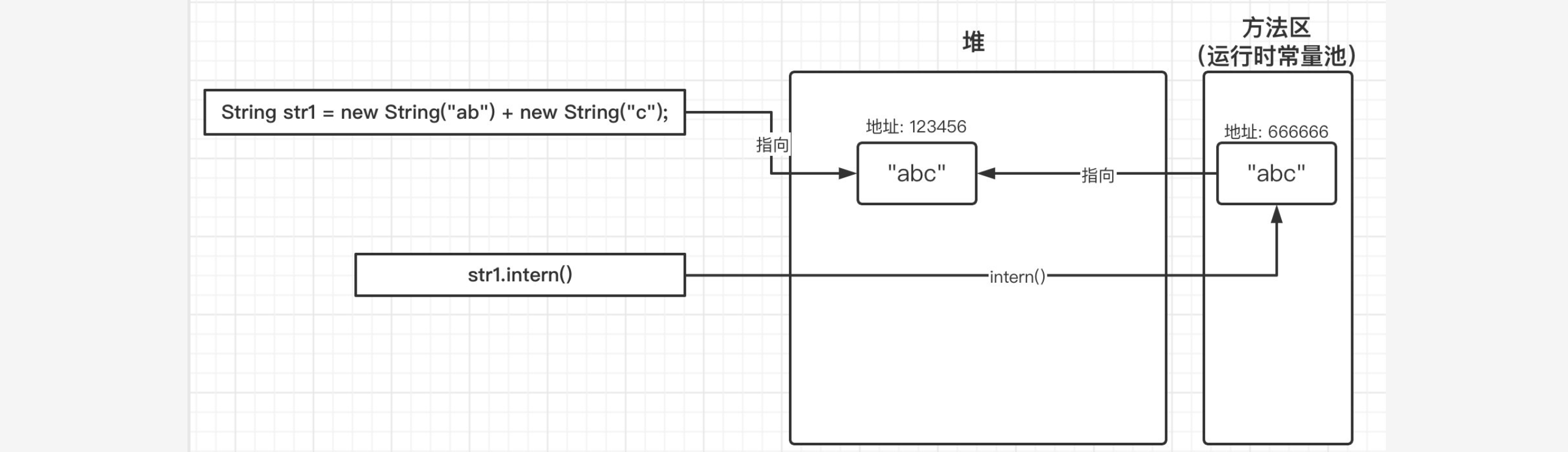
1 | public static void main(String[] args) { |
所以最后我们会发现,str1.intern()和str1都是同一个对象,结果为true。
最后我们再来进行一个总结,各个内存区域的用途:
- (线程独有)程序计数器:保存当前程序的执行位置。
- (线程独有)虚拟机栈:通过栈帧来维持方法调用顺序,帮助控制程序有序运行。
- (线程独有)本地方法栈:同上,作用与本地方法。
- 堆:几乎所有的对象和数组都在这里保存,字符串常量池。
- 方法区:类信息、即时编译器的代码缓存、运行时常量池。
爆内存和爆栈
实际上,在Java程序运行时,内存容量不可能是无限制的,当我们的对象创建过多或是数组容量过大时,就会导致我们的堆内存不足以存放更多新的对象或是数组,这时就会出现错误,比如:
1 | public static void main(String[] args) { |
这里我们申请了一个容量为21亿多的int型数组,显然,如此之大的数组不可能放在我们的堆内存中,所以程序运行时就会这样:
1 | Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit |
这里得到了一个OutOfMemoryError错误,也就是我们常说的内存溢出错误。我们可以通过参数来控制堆内存的最大值和最小值:
1 | -Xms最小值 -Xmx最大值 |
比如我们现在限制堆内存为固定值1M大小,并且在抛出内存溢出异常时保存当前的内存堆转储快照:
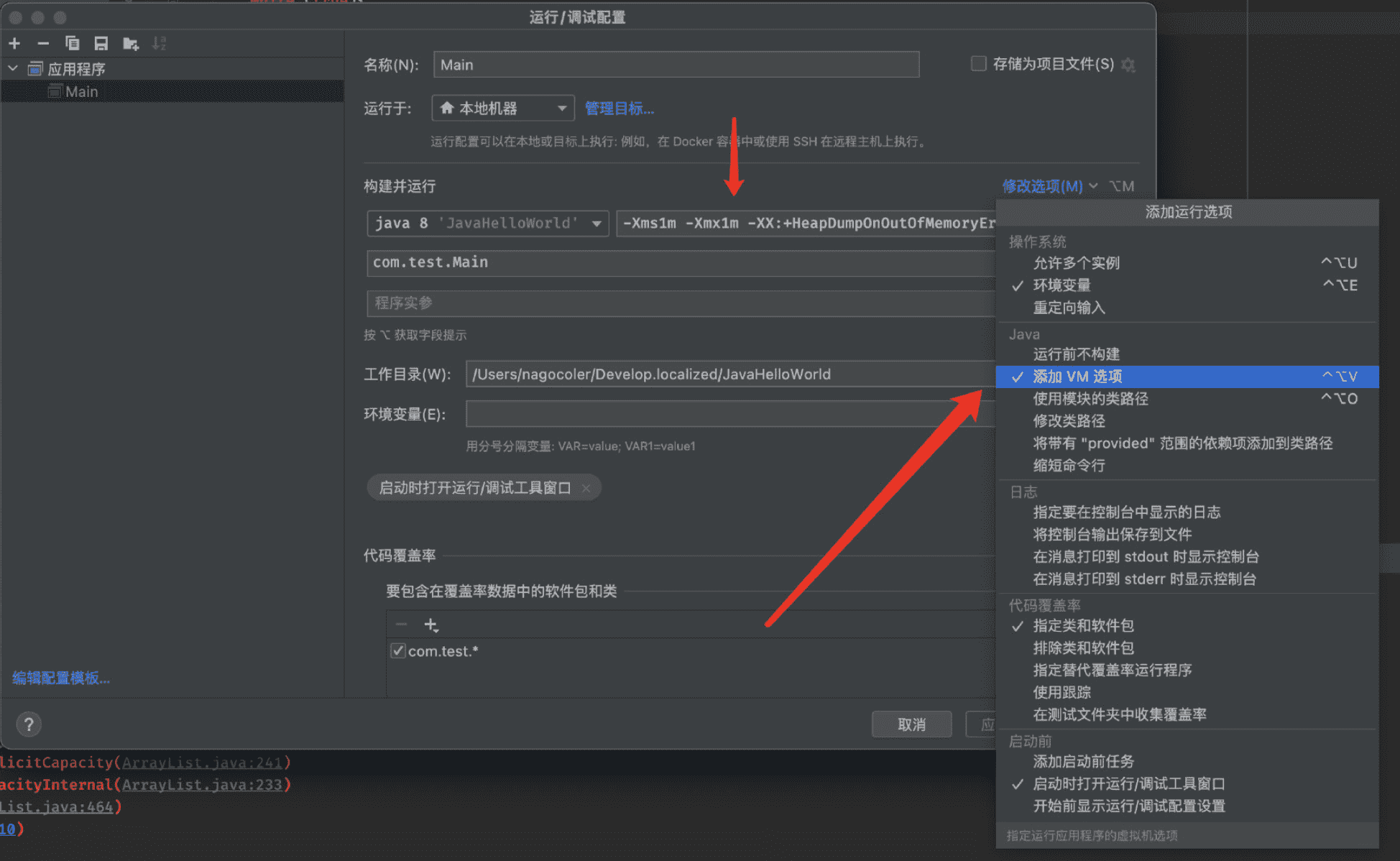
注意堆内存不要设置太小,不然连虚拟机都不足以启动,接着我们编写一个一定会导致内存溢出的程序:
1 | public class Main { |
在程序运行之后:
1 | java.lang.OutOfMemoryError: Java heap space |
可以看到错误出现原因正是Java heap space,也就是堆内存满了,并且根据我们设定的VM参数,堆内存保存了快照信息。我们可以在IDEA内置的Profiler中进行查看:
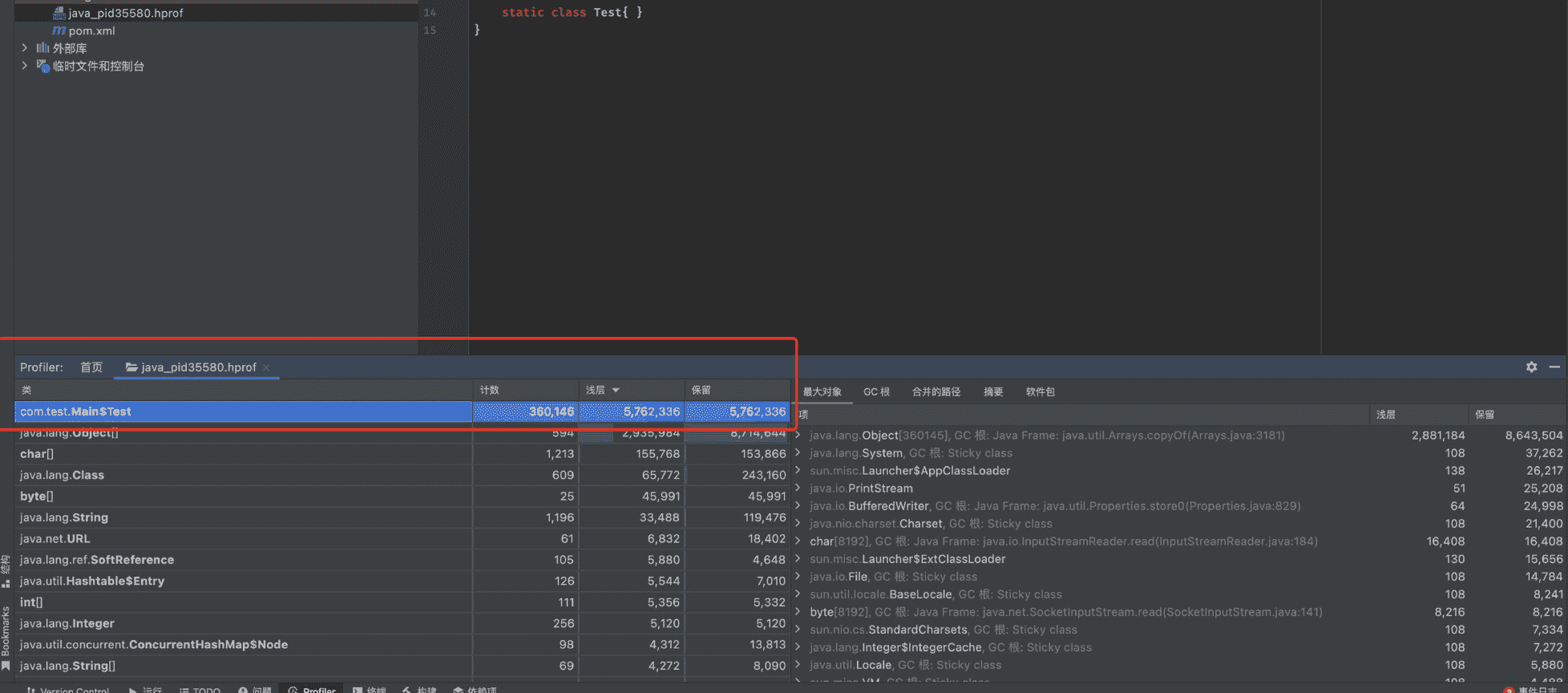
可以很明显地看到,在创建了360146个Test对象之后,堆内存不够了,于是就抛出了内存溢出错误。
我们接着来看栈溢出,我们知道,虚拟机栈会在方法调用时插入栈帧,那么,设想如果出现无限递归的情况呢?
1 | public class Main { |
这很明显是一个永无休止的程序,并且会不断继续向下调用test方法本身,那么按照我们之前的逻辑推导,无限地插入栈帧那么一定会将虚拟机栈塞满,所以,当栈的深度已经不足以继续插入栈帧时,就会这样:
1 | Exception in thread "main" java.lang.StackOverflowError |
这也是我们常说的栈溢出,它和堆溢出比较类似,也是由于容纳不下才导致的,我们可以使用-Xss来设定栈容量。
申请堆外内存
除了堆内存可以存放对象数据以外,我们也可以申请堆外内存(直接内存),也就是不受JVM管控的内存区域,这部分区域的内存需要我们自行去申请和释放,实际上本质就是JVM通过C/C++调用malloc函数申请的内存,当然得我们自己去释放了。不过虽然是直接内存,不会受到堆内存容量限制,但是依然会受到本机最大内存的限制,所以还是有可能抛出OutOfMemoryError异常。
这里我们需要提到一个堆外内存操作类:Unsafe,就像它的名字一样,虽然Java提供堆外内存的操作类,但是实际上它是不安全的,只有你完全了解底层原理并且能够合理控制堆外内存,才能安全地使用堆外内存。
注意这个类不让我们new,也没有直接获取方式(压根就没想让我们用):
1 | public final class Unsafe { |
所以我们这里就通过反射给他搞出来:
1 | public static void main(String[] args) throws IllegalAccessException { |
成功拿到Unsafe类之后,我们就可以开始申请堆外内存了,比如我们现在想要申请一个int大小的内存空间,并在此空间中存放一个int类型的数据:
1 | public static void main(String[] args) throws IllegalAccessException { |
我们可以来看一下allocateMemory底层是如何调用的,这是一个native方法,我们来看C++源码:
1 | UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory0(JNIEnv *env, jobject unsafe, jlong size)) { |
接着来看:
1 | void* os::malloc(size_t size, MEMFLAGS flags) { |
所以,我们上面的Java代码转换为C代码,差不多就是这个意思:
1 |
|
所以说,直接内存实际上就是JVM申请的一块额外的内存空间,但是它并不在受管控的几种内存空间中,当然这些内存依然属于是JVM的,由于JVM提供的堆内存会进行垃圾回收等工作,效率不如直接申请和操作内存来得快,一些比较追求极致性能的框架会用到堆外内存来提升运行速度,如nio框架。




